
안녕하세요. 스포카 백엔드팀 프로그래머 이지민입니다.
스포카에서는 식당 점주분들이 식자재 주문을 더 편리하게 하기 위한 많은 노력들을 하고 있습니다. 그중에서도, 주문하려는 품목을 검색하여 원하는 품목을 빠르게 찾을 수 있도록 품목 검색 기능을 제공하고 있는데요.
검색 엔진 도입부터 지금의 검색이 되기까지의 과정들을 이야기해보려고 합니다.
도입 초기에는 검색 엔진에 대한 이해가 깊지 않아, 논리적인 의사결정보다는 다양한 테스트를 통해 더 나은 결과를 찾는 방식으로 기능을 결정, 구현하였습니다. 이 점을 고려해 읽어주시길 바라며, 이 글은 검색 엔진의 점진적인 발전 과정을 다루는 이야기이니, 순차적으로 읽어보시면 개선 과정이 더욱 잘 이해되실 것 같습니다!
검색 엔진 도입 배경
품목 검색 기능 초기에는 Database의 LIKE 질의를 통한 검색만 제공되었습니다. 이로 인해 품목명에 띄어쓰기가 다르거나 맞춤법이 정확히 일치하지 않는 경우, 사용자가 원하는 결과를 찾기가 어려웠습니다.
예를 들어, 깐마늘을 검색했을 때 마늘/깐 이라고 저장되어 있는 유통사 품목은 검색되지 않아 점주들은 깐마늘을 유통사가 취급하지 않는다고 오해하는 상황이 발생하곤 했습니다.
이와 같은 문제와 사용하는 점주의 수가 증가하고 품목의 종류가 다양해짐에 따라, DB 검색 기능의 한계가 더 드러나게 되었고 이를 해결하기 위해 검색 엔진 도입의 필요성이 대두되었습니다.
이번 검색 엔진 도입이 스포카에서 최초 도입은 아닌데요.(하지만 제가 처음이에요.) (구)도도카트 서비스 운영 당시 많은 명세표 품목을 검색하는데 Elasticsearch 검색 엔진을 활용했었습니다. 우선 별도의 검색 품질에 대한 기준이 마련되어 있지 않았기 때문에 (구)도도카트 서비스의 검색 엔진 설정을 참고해 Elasticsearch(이하 ES)를 POC 해보기로 했습니다.

DB LIKE 검색과 ES 검색 비교 POC
품목 데이터는 product 라는 인덱스에 다음과 같은 setting 으로 구성했습니다.
{
"product":{
"mappings":{
"properties":{
// .. 생략
"name":{
"type":"text",
"analyzer":"korean",
"fields":{
"ngram":{
"type":"text",
"analyzer":"korean_ngram"
}
}
}
}
},
"settings":{
"index":{
"analysis":{
"filter":{
"edge_ngram_back":{
"min_gram":"1",
"side":"back",
"type":"edge_ngram",
"max_gram":"5"
},
"edge_ngram_front":{
"min_gram":"1",
"side":"front",
"type":"edge_ngram",
"max_gram":"5"
}
},
"analyzer":{
"korean":{
"filter":[
"lowercase",
"trim"
],
"type":"custom",
"tokenizer":"nori_mixed"
},
"korean_ngram":{
"filter":[
"lowercase",
"edge_ngram_front",
"edge_ngram_back",
"trim"
],
"type":"custom",
"tokenizer":"nori_mixed"
}
},
"tokenizer":{
"nori_mixed":{
"type":"nori_tokenizer",
"decompound_mode":"mixed"
}
}
}
}
}
}
}
- 품목명을 저장할
namefield,name.ngramfield 구현 - 한글 검색의 정확성과 유연성을 높이기 위해 Nori Tokenizer와 Edge N-gram 필터를 활용해 띄어쓰기나 일부 단어만으로도 검색이 가능하도록 설정
또한, LIKE 질의를 사용하는 기존 DB 검색과 ES 검색의 결과를 비교한 POC 결과는 다음과 같습니다.
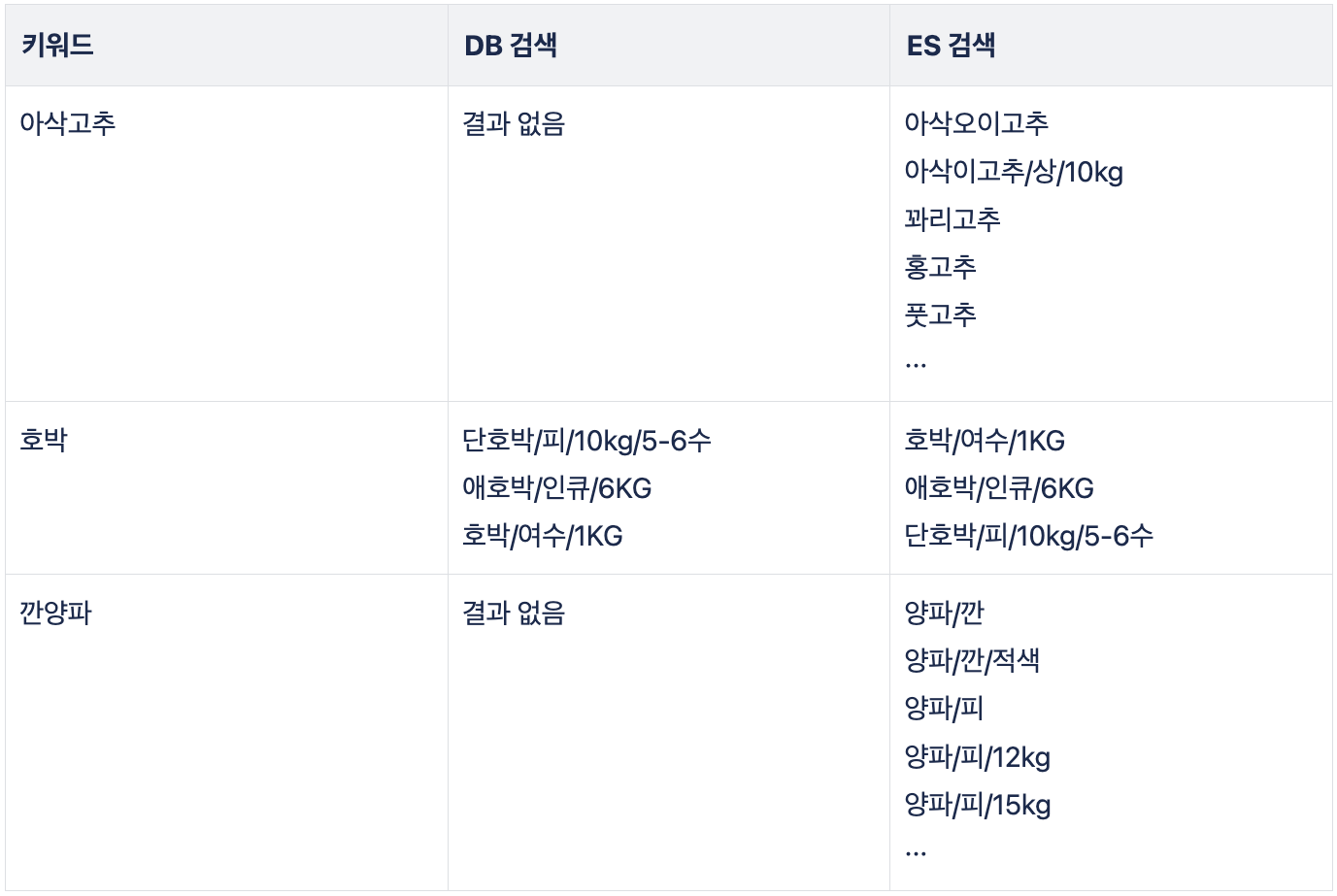
결과를 통해 볼 수 있듯이, 정확하지 않은 키워드로 검색했을 때도 기존 DB의 LIKE 질의보다 ES 검색이 훨씬 더 나은 결과를 제공하는 것을 확인할 수 있었습니다.
비용 증가와 관리 포인트가 늘어남에도 불구하고 앞서 언급한 문제들이 해소되었고 검색 품질을 크게 항상시킬 수 있을거 같아 검색 엔진 도입을 최종적으로 결정하게 되었습니다!
다만, 이번 테스트는 전체 검색어가 아닌 일부 검색어를 대상으로 진행된 POC 였기 때문에, 실제 사용자의 피드백을 바탕으로 지속적인 수정과 개선이 필요할 것으로 예상하고 있었습니다. 이러한 부분을 미리 인지하고 마음의 준비(?)와 공부를 하고 있었죠.
개선 작업
1) 가중치 조절 및 N-gram 조정
이슈 및 원인 분석
검색 엔진을 적용한 후에 아래와 같은 피드백이 들어왔습니다.
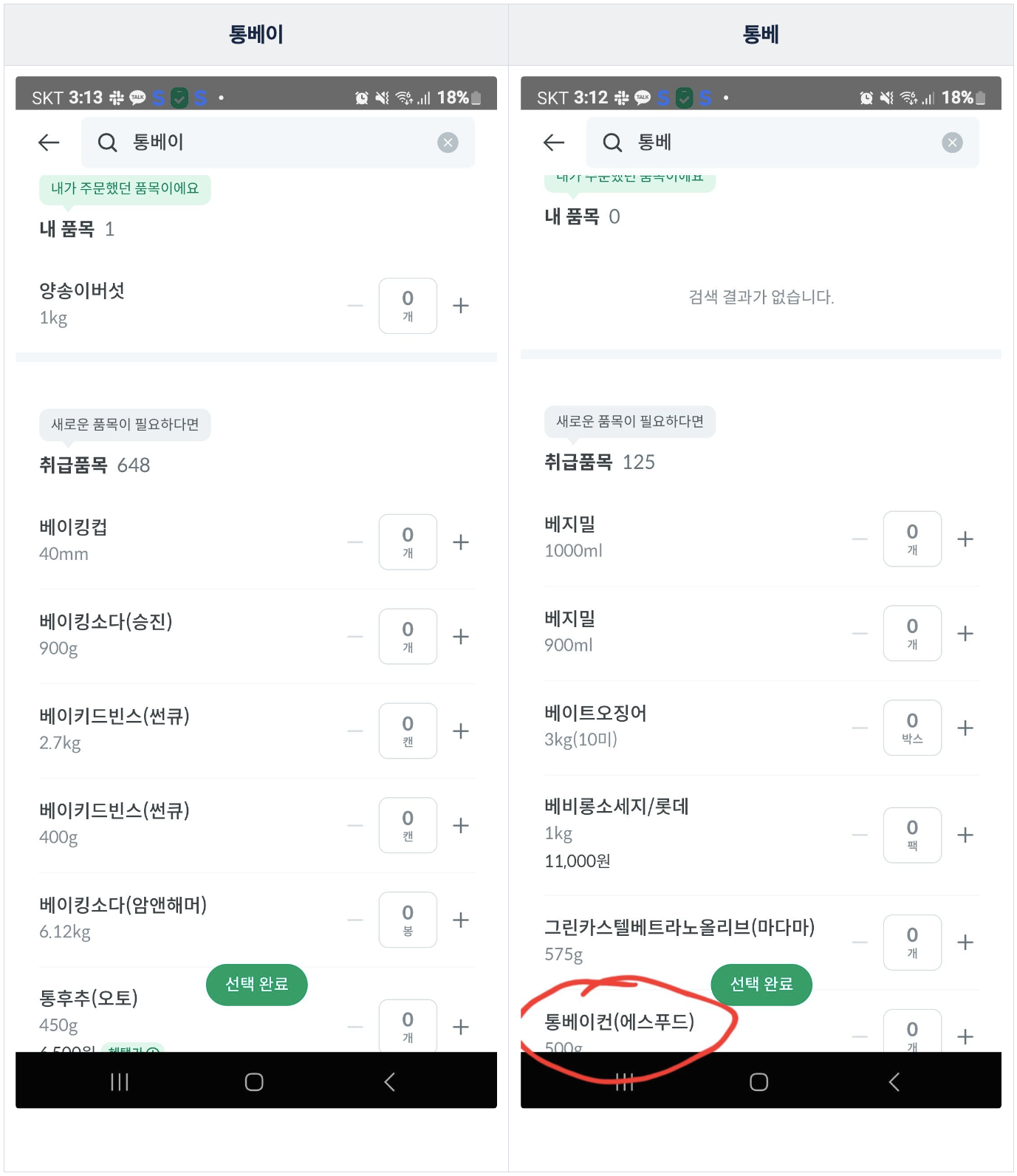
주문하려고 했던 품목은 통베이컨(에스푸드)였지만, 통베, 통베이 키워드로 검색했을 때 상위에 노출되지 않는다는 이슈였습니다.
이 문제를 해결하기 위해, 우선 통베라는 검색어를 중심으로 원인을 분석해보았습니다.
문제 원인 파악을 위해 _analyze API를 활용하여 name 필드에 적용된 분석기(analyzer)가 검색어를 어떻게 토큰화하는지 살펴보았습니다.
GET product/_analyze
{
"field" : "name",
"text" : "통베이컨(에스푸드)"
}
Response
{
"response":{
"tokens":[
{
"token":"통",
"start_offset":0,
"end_offset":1,
"type":"word",
"position":0
},
{
"token":"베이컨",
"start_offset":1,
"end_offset":4,
"type":"word",
"position":1
},
{
"token":"에스",
"start_offset":5,
"end_offset":7,
"type":"word",
"position":2
},
{
"token":"푸드",
"start_offset":7,
"end_offset":9,
"type":"word",
"position":3
}
]
}
}
결과는 [통, 베이컨, 에스, 푸드] 로 예측 가능하게 나오네요.
그러나 문제의 검색어인 통베는 다음과 같이 토큰화되었습니다:
[통, 베, 베, 어]
잠깐 어 는 뭐지? 라고 생각하실 수 있는데요. 통베라는 단어 어디에도 어 라는 단어는 찾아볼 수 없기 때문이죠.
이는 ES의 Nori Tokenizer 가 한국어 문장에서 어미를 추출하는 방식을 따라 토큰화하기 때문입니다.
예를 들어, “강아지가 밥을 먹습니다”라는 문장은 [강아지, 가, 밥, 을, 먹, 습니다]로 명사와 어미를 구분하여 토큰화됩니다.
따라서 정확히 알기는 어렵지만 어는 Nori Tokenizer 가 베에서 어미로 분리한 결과로 예상하고 있어요.
이런 토큰화 방식을 보고 Nori Tokenizer 의 토큰화는 단어별로 검색하는 패턴이 많은 저희 서비스에서 예측 불가능할 수 있겠다라는 깨달음을 얻었어요. 하지만 Nori를 아예 제거하기엔 Nori 가 해주는 명사 추출의 이점이 있을 수 있어 조심스러웠습니다. 결론적으로, Nori 기능을 완전히 제거하는 대신, 다른 접근을 시도하기로 했습니다.
쿼리 가중치 조절 POC
문제 해결을 위해 쿼리의 가중치를 조절해보기로 했습니다.
기존엔 쿼리 가중치를 순수 Nori Tokenizer 가 적용된 name 필드와 Nori Tokenizer 와 N-gram filter 가 적용된 name.ngram 필드에 각각 10과 5 를 주고 있었는데요.
따라서 N-gram 에 의해 검색된 품목보다 순수 Nori 에 의해 검색된 품목의 유사도가 높아져 상위에 올라가게 됩니다.
통베 라고 검색했을때 통베이컨(에스푸드) 품목이 올라오기 위한 가중치 조절과 N-gram Filter 조정이 필요해보였습니다.
 최적의 가중치와 N-gram Filter 설정을 찾기 위해 통베이컨 품목을 기준으로
최적의 가중치와 N-gram Filter 설정을 찾기 위해 통베이컨 품목을 기준으로 삽질을 테스트를 아래와 같이 해보았는데요.
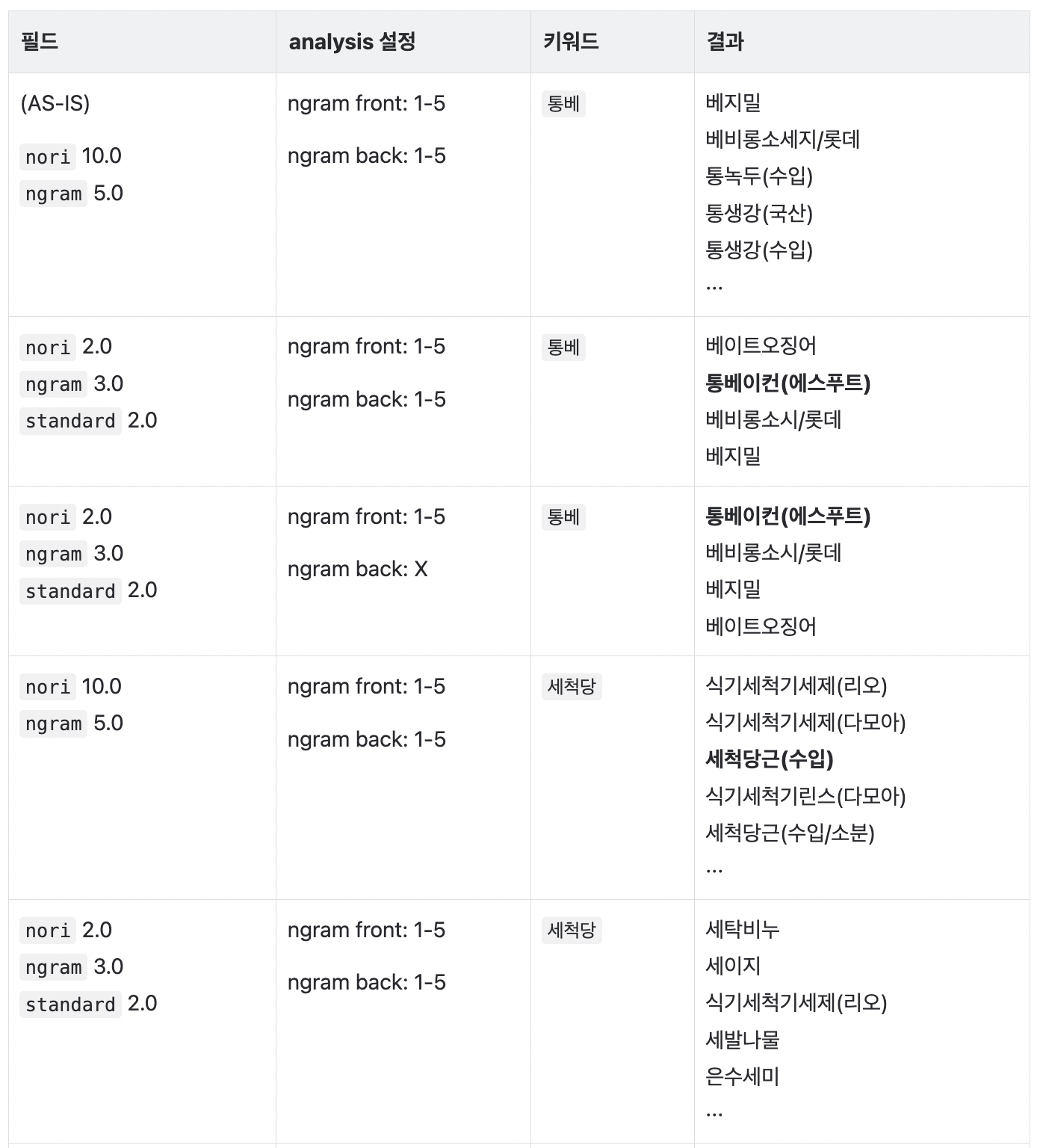
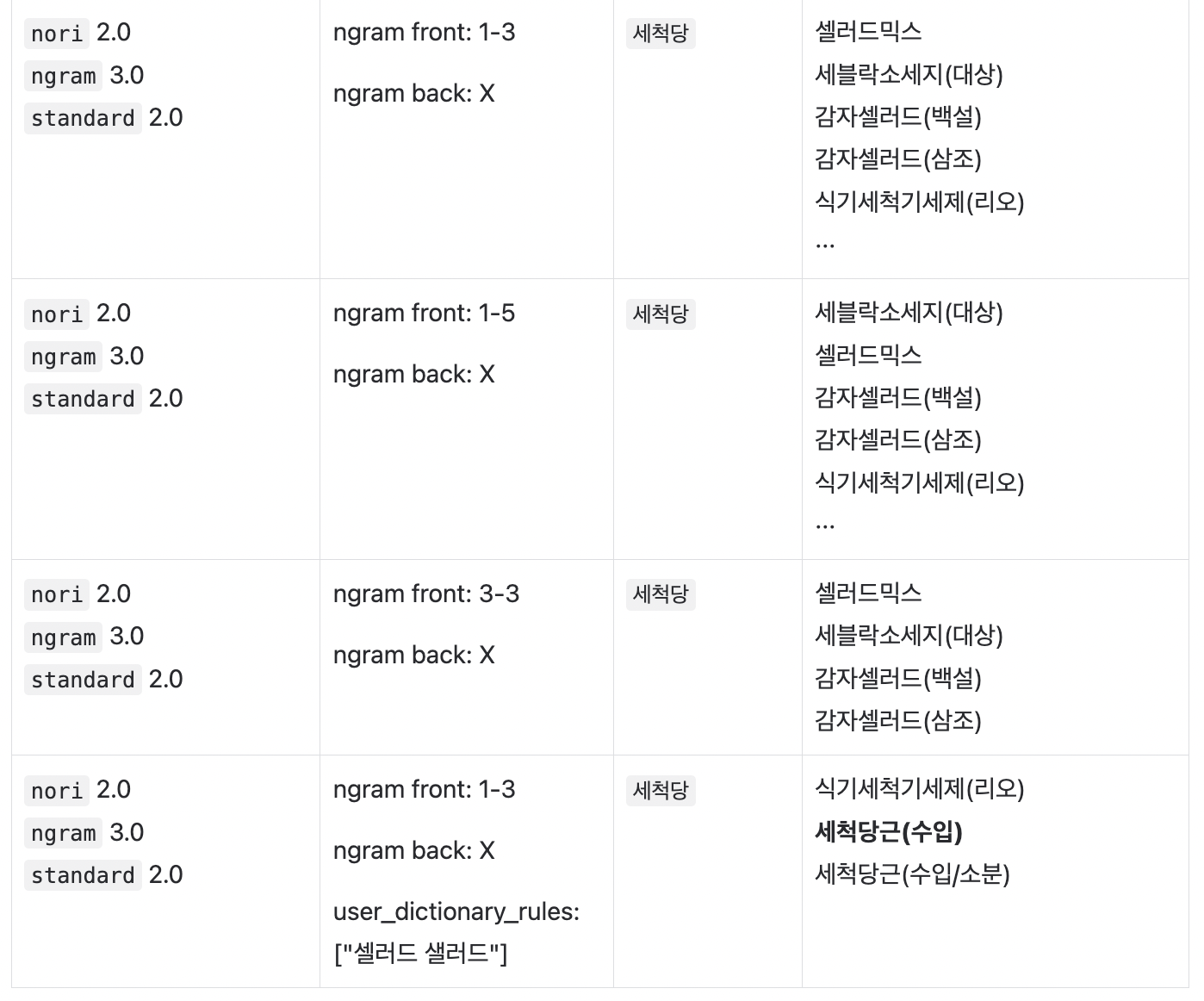
Nori Tokenizer 에만 의존하기에는 무리가 있을거 같아 ES 기본 Tokenizer 인 Standard Tokenizer 도 추가해서 테스트 해봤습니다.
가중치의 경우, 순수 Nori 인 nori 와 N-gram 을 적용한 ngram, standard 필드의 가중치를 조정해보며 각각 2.0, 3.0, 2.0 일 때 통베이컨(에스푸드)와 세척당근이 가장 잘 검색되는 것을 확인 했습니다.
여기에서 Edge N-gram 에 대해서 간단히 설명드리자면요.
{
"min_gram": "1",
"max_gram": "3",
"side": "front",
"type": "edge_ngram"
}
- min_gram : 최소 토큰 길이
- max_gram : 최대 토큰 길이
- side : 단어의 어느 부분부터 토큰화 할지 설정(front/back)
side 가 front 인 위 예시로 안녕하세요를 토큰화해보면 [안, 안녕, 안녕하]로 토큰화되고 side 가 back 일 경우엔 [요, 세요, 하세요]로 토큰화 됩니다.
때문에 front 의 경우 주로 첫 글자부터 검색하는 자동완성과 같은 곳에서 사용하고 back 은 주로 뒷글자부터 검색하는 경우, 예를들면 영어로 ion 을 검색했을 때 action, station, evolution 같은 것들을 검색할 때 유용하게 사용할 수 있을거예요.
저희는 식자재 검색라는 특성이 있어 통베, 세척당과 같이 앞글자부터 검색하는 경우가 많기 때문에 back 은 제거하고 front 만 남기기로 했습니다. max_gram 도 기존엔 5로 토큰화가 많이 되어 오히려 정확성을 떨어트리는 것을 발견했고 적절해보이는 3으로 조정했습니다.
결론
결론적으로 아래 조정 작업으로 문제가 되었던 품목이 검색 상위에 안정적으로 노출되도록 검색 품질을 향상시켰습니다.
- N-gram 조정:
max_gram값을 5 -> 3으로 하향 조정하고side: front만 사용 - 가중치 조정: Nori, N-gram, Standard 분석기의 가중치를 적절히 분배
2) Wildcard 검색
이슈 및 원인 분석
위 작업을 배포하고 내부에서 아래와 같은 피드백을 받았습니다.

칠성사이다/355ml*24캔라는 품목이 있는데도 불구하고 사이다 라고 검색했을때 검색이 되지 않는 이슈였는데요.
각 분석기에서 칠성사이다/355ml*24캔이 토큰화된 결과는 다음과 같았습니다.
Nori: 칠성사, 칠, 성사, 이, 다, 355, ml, 24, 캔
N-gram: 칠, 칠성, 칠성사, 칠, 성, 성사, 이, 다, 3, 35, 355, m, ml, 2, 24, 캔
Standard: 칠성사이다, 355ml, 24캔
결과에서 확인할 수 있듯이, 사이다라는 토큰이 생성되지 않아 검색 결과에서 제외된 것입니다.
위에서 가중치와 N-gram 을 조정했는데도 불구하고 왜 사이다로 토큰화되지 않았을까요? 이는 N-gram 은 Filter 이기 때문에 Nori 분석기에서 생성된 토큰을 기반으로 토큰을 더 잘게 나누는 필터링을 수행하기 때문이에요. 즉, Nori 분석기가 사이다를 하나의 단어로 인식하지 못하고 어미(이, 다)로 나누어버렸기 때문에, 사이다라는 토큰 자체가 존재하지 않았던 것이죠,,
만약 칠성고구마였다면 어떻게 되었을까요?
nori: [칠성, 고구마, 355, ml, 24, 캔]
ngram: [칠, 칠성, 고, 고구, 고구마, 3, 35, 355, m, ml, 2, 24, 캔]
standard: [칠성고구마, 355ml, 24캔]

이처럼 명사 단위로 토큰화하기 때문에 Nori 명사 사전에 명사 존재 여부에 따라 토큰화가 다르게 됩니다. 명사 사전에 존재하는 품목의 경우, 고구마처럼 검색이 훨씬 매끄러울 수 있을거예요.
사이다도 명사 사전에 등록되어 있었다면 칠성사이다도 [칠성, 사이다] 로 토큰할 수 있었겠죠.
User Dictionary
따라서, 사용자 사전(user_dictionary) 도입을 고려했었는데요. Nori Tokenizer 에게 사이다는 명사야, 혹은 칠성사이다는 [칠성, 사이다] 라고 토큰화 해! 라고 인식할 수 있는 기준을 마련해줄수있는 방법이에요.
하지만 몇가지 한계가 있었어요.
- 관리 포인트 증가
- 관리해야 할 품목의 종류가 너무 많아 어려움이 발생
- 농산물, 곡류, 축산물, 수산물 등 수백에서 수천 가지 품목을 주기적으로 업데이트하기 어려운 환경
- 표준화되지 않은 품목명
- 유통사마다 다른 표기 방식으로 인해 같은 품목도 명칭이 다름
- 예: “무”와 “무우”, “샐러드”와 “셀러드” 등 비표준어와 잘못된 외래어 표기
- 이러한 다양한 표기법을 모두 관리하기엔 부담이 큼
이러한 이유로 사용자 사전을 유지 관리하는 것이 현실적으로 어렵다고 판단하여 다른 접근 방식을 찾기로 했습니다.
Wildcard Field
문제를 다시 분석한 결과, 검색어 자체가 포함된 품목을 반환하는 것이 핵심이라는 점을 확인했습니다. 이는 마치 DB의 LIKE 쿼리처럼 검색어가 포함된 품목을 반환하는 것이죠. ES에서는 이러한 기능을 제공하는 Wildcard 필드를 활용할 수 있었습니다.
Wildcard 필드를 추가하는 방법은 간단합니다.
{
"mappings":{
"properties":{
"name":{
"type":"text",
"analyzer":"korean",
"fields":{
// .. 생략
"wildcard":{
"type":"wildcard"
}
}
}
//.. 생략
}
}
}
Wildcard 필드는 역색인 구조가 아닌 패턴 매칭 방식을 사용하기 때문에 성능 문제가 발생할 수 있어서 신중히 사용해야 합니다. 모든 토큰을 검사해야 하기 때문에 데이터가 많아질수록 메모리 사용량이 많아지고 성능이 떨어질 수 있습니다. 따라서 Wildcard 필드 대신 정교한 N-gram 을 사용하거나 Query-String 쿼리를 권장합니다.
하지만 저희는 데이터량이 많지 않고, 필터를 통해 조회되는 데이터 수를 제한할 수 있었기 때문에 성능 부담이 아직까진 크지 않아 Wildcard 필드를 사용하기로 결정했습니다.
Wildcard 필드를 활용한 쿼리는 다음과 같이 구성했습니다:
{
"query":{
"bool":{
"must":[
{
"bool":{
"should":[
{
"wildcard":{
"name.wildcard":{
"boost":100.0,
"wildcard":"*사이다*"
}
}
},
{
"multi_match":{
"fields":[
"name^3.0",
"name.ngram^4.0",
"name.standard^3.0"
],
"query":"사이다"
}
}
]
}
}
]
}
}
}
검색어가 포함된 결과는 상단으로 올리되, 포함된 결과 내에서도 유사도에 맞게 정렬되도록 쿼리를 수정했습니다. 위처럼 할 경우 사이다가 포함된 단어는 100 점을 추가로 받고 match 되는 필드에 따라 점수를 추가로 더해지게 됩니다.
예를들어 칠성사이다 , 칠십성사이다 , 칠성사이 라는 품목이 있을때, 사이다 라고 검색하면 wildcard 에 의해 칠성사이다, 칠십성사이다 가 가장 상단으로 나오게 될테고, 품목의 이름이 더 짧아 유사도가 더 높은 칠성사이다 가 최상단으로 나오게 될거예요.
기존의 가중치는 유지하되 검색어가 포함된 결과만 올리기 위한 쿼리입니다.
결론
- User Dictionary 도입을 고려했으나 유지보수에 대한 한계로 제외
- Wildcard 필드와 쿼리로 검색어가 포함된 품목의 점수를 높임
3) 초성 검색 feat. ICU
Wildcard 검색까지 구현하고 나니 검색 되지 않는 품목 없이 꽤 안정화된 검색 결과를 제공할 수 있었는데요. 더 편리한 검색을 위한 초성 검색 니즈가 들어 왔습니다.
어떤 extension 을 사용할 것인가
초성검색을 위해 지금 시스템에 도입할 수 있고, 적당한 레퍼런스가 있는 두가지 extension으로 POC 를 진행해봤어요.
- elasticsearch-jaso-analyzer(이하 JASO)
- analysis-icu(이하 ICU)
결론적으로 ICU 를 선택했는데요, JASO 에 대한 설명이 너무 길어질거 같아 자세한 설정 방법과 설명은 위 주소에서 참고주시길 바랍니다. 두 분석기를 비교한 결과는 아래 표로 정리되었습니다.
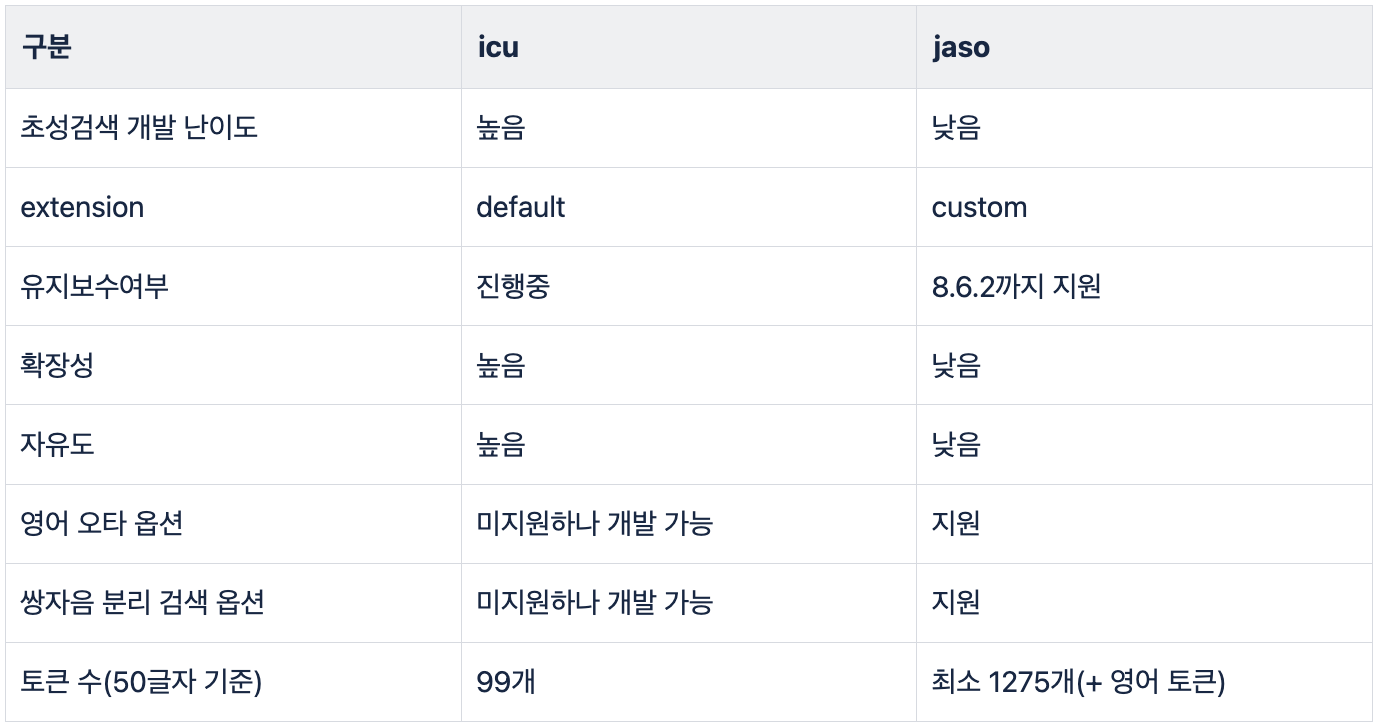
- 개발 난이도
- JASO:
"chosung"옵션만 추가하면 간단히 초성 검색이 가능 - ICU: 직접 초성 필터를 구현해야 하는 추가 작업 필요
- JASO:
- 유지보수 및 확장성
- JASO: 커스텀 확장(extension)으로 기본 제공되지 않기 때문에, 사용하는 ES 버전과 플랜에 따라 제약이 있을 수 있음
- ICU: 기본 확장(extension)으로 계속 지원되며, 다른 기능으로의 확장이 자유로움
- 버전 지원
- JASO: Elasticsearch 8.6.2까지만 지원. 이후 버전은 직접 설정 필요
- ICU: 최신 버전까지 지원
- 토큰 생성 방식
- JASO: 영어 오타 교정, 쌍자음 분리 등 추가 기능 지원
- ICU: 필요에 따라 초성 검색뿐만 아니라 다양한 확장 가능
JASO 가 더 많은 옵션을 제공한다는 이점이 있지만 불필요한 토큰이 생성되고 큰 max_gram을 주어 토큰을 많이 생성해야 된다는 점,
유지보수를 직접 해야된다는 점에서 ICU extension 을 직접 확장하여 사용하기로 하였습니다.
ICU Analyzer
그럼, ICU analyzer 의 설정을 좀더 자세히 살펴보겠습니다.
{
"orderable_vendor_product_v4":{
"aliases":{
"orderable_vendor_product":{}
},
"mappings":{
"properties":{
// .. 생략
"name":{
"type":"text",
"fields":{
"icu":{
"type":"text",
"analyzer":"icu_analyzer",
"search_analyzer":"icu_search_analyzer",
"similarity":"scripted_no_idf"
}
}
}
}
}
},
"template":{
"settings":{
"index":{
"analysis":{
"filter":{
// .. 생략
"ngram_filter":{
"type":"ngram",
"min_gram":1,
"max_gram":2,
"token_chars":[
"letter",
"digit"
]
}
},
"analyzer":{
// .. 생략
"icu_analyzer":{
"type":"custom",
"filter":[
"lowercase",
"ngram_filter"
],
"char_filter":[
"nfd_normalizer",
"make_chosung_filter"
],
"tokenizer":"icu_tokenizer"
},
"icu_search_analyzer":{
"type":"custom",
"filter":[
"lowercase",
"ngram_filter"
],
"char_filter":[
"chosung_only_filter",
"nfd_normalizer"
],
"tokenizer":"icu_tokenizer"
}
},
"char_filter":{
"nfd_normalizer":{
"mode":"decompose",
"name":"nfkc",
"type":"icu_normalizer"
},
"make_chosung_filter":{
"type":"pattern_replace",
"pattern":"[^\u1100-\u1112^0-9a-zA-Z가-힣ㄱ-ㅎ ㅏ-ㅑ]",
"replacement":""
},
"chosung_only_filter":{
"type":"pattern_replace",
"pattern":"[^ㄱ-ㅎa-zA-Z0-9]",
"replacement":""
}
}
//.. 생략 Tokenizer
}
}
}
}
}
위 analzyer 를 그림으로 나타내면 아래와 같습니다.
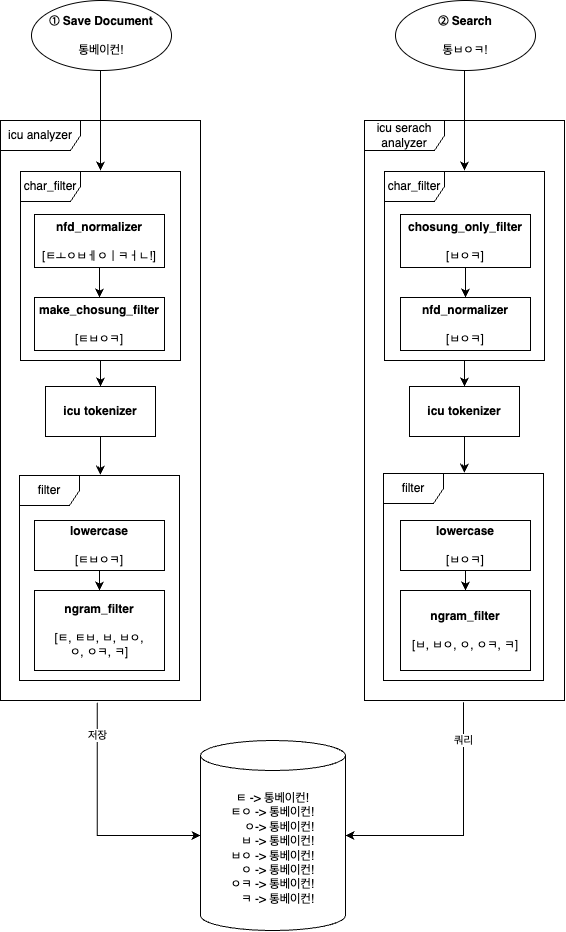
icu field 를 보시면 analyzer 와 search_analyzer 를 구분해서 설정해준걸 보실 수 있는데요.
- Analyzer : 저장되는 document 에 대해서 토큰화하여 그림과 같이 역색인화 구조로 저장합니다.
- Search Analyzer : 검색어에 대해서 토큰화를 수행해서 저장되어 있는 토큰을 검색해서 결과를 내는 역할을 합니다.
기존엔 Analyzer 와 Search Analyzer 를 구분해서 지정해줄 필요가 없었지만 초성 검색의 경우엔 초성으로 검색 했을 때만 초성 검색이 되길 바랬었는데요.
예를 들어 초성이 아닌 통베이컨을 Analyzer 로 검색했을 경우, ㅌㅂㅇㅋ 으로 초성화 될 것이고 사용자가 초성 검색을 하지 않았는데도 초성을 포함하는 품목이 많이 나오게 될 것 입니다.
그래서 최대한 기존의 쿼리 score 에는 영향이 가지 않고 초성 검색을 했을때만 초성으로 품목을 찾기 위해서 초성을 제외한 글자는 모두 제거하는 필터를 넣는 Search Analyzer 를 따로 지정해주었습니다.
즉, 통베이컨이 Search Analyzer 를 거치게 되면 아무 토큰도 생성되지 않게 되어 초성 검색에 대해서는 수행이 되지 않게 되는거죠.
ICU_Normalizer 에 대한 설정은 문서를 보시면 더 자세히 볼 수 있을거예요. 요약하자면 유니코드의 정규화(Normalization)를 수행하는 역할을 합니다.
저희는 decompose 옵션을 사용하여 통이라는 글자를 ㅌㅗㅇ 으로 문자를 분해할 수 있도록 했고, NFKC(Normalization Form Compatibility Composition) 옵션을 사용하여 호환가능한 문자를 호환시키고, 조합 가능한 문자는 조합하도록 설정하였습니다.
즉, 통베이컨™①é를 정규화하면 ㅌㅗㅇㅂㅔㅇㅣㅋㅓㄴTM1é로 정규화 됩니다.
초성검색 구현을 위해선 정규화 방식보다는 초성 분리를 위한 mode 를 잘 설정하는게 더 핵심이라고 할 수 있을거예요.
요약하면 품목을 ICU Normalizer 를 활용하여 초성 토큰 형태로 저장하고, 초성 검색어에 대해서만 초성 검색을 수행할 수 있도록 Search Analyzer 를 구분하여 구현해주었습니다.
ICU 는 JASO와 비교했을 때 초기 구현은 다소 복잡했지만, 유지보수와 추후 확장성 측면에서 더 적합한 선택이었으면 합니다!! (Extension 교체 작업만은 다시 하고 싶지 않아요..)
IDF 제외
이제 마지막 개선 작업이네요. 잘 운영하고 있던 중 아래와 같은 의견이 들어왔습니다.
이슈 및 원인 분석
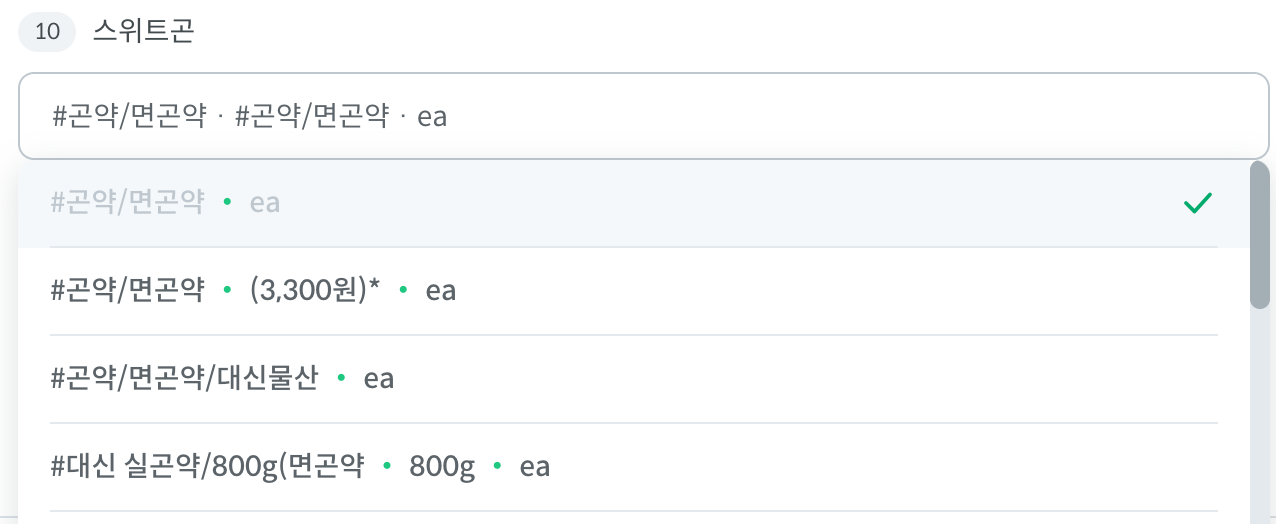
사용자가 스위트콘을 검색하려 했으나 스위트곤으로 오타가 발생한 경우, 기대했던 스위트콘이 아닌 곤약이 상위에 노출되는 문제가 있었습니다. 일반적으로 사용자가 기대하는 결과와는 다른 결과였죠.
다행히도 로컬 테스트 환경에서 원인 분석을 해볼 수 있었는데요, 그런데 조금 충격적이게도 로컬에선 스위트콘이 더 상위노출 되었습니다. 이럴수가..
그렇다는 것은 로컬 테스트코드와 실제 환경의 검색 결과가 다르다는 것이고, 지금까지의 테스트가 유효한게 맞을까.. 하는 생각이 들었는데요.

더 자세한 원인을 파악하기 위해 ES의 explain API를 사용해 점수 산출 과정을 분석했습니다.
결과를 요약하자면 아래와 같은데요.
#곤약/면곤약- N-gram Boost : 8.8
- IDF: 6.05
- TF: 0.78
- 8.8 * 6.05 * 0.78 = 41.66
스위트콘/리치스/2.95kg- N-gram Boost : 8.8
- IDF : 3.14
- TF : 0.81696963
- 8.8 * 3.14 * 0.81696963 = 22.568493
ES 에서 Boost * IDF * TF 계산 로직을 통해 score 를 산출하고 있었습니다. 곤약이 상위로 올라온 이유는 숫자를 보면 알수있듯 두배 가까이 차이나는 IDF 때문인 것을 파악할 수 있었는데요.
우선 처음 보는 개념인 IDF 와 TF 가 무엇인지 알아보았습니다.
- IDF(Inverse Document Frequency): 특정 단어가 전체 문서에서 얼마나 드물게 나타나는지
- TF(Term Frequency): 특정 단어가 문서 내에서 얼마나 자주 나타나는지
IDF 는 전체 문서를 기준으로 계산되기 때문에 테스트코드와 실제 환경의 결과가 다른 이유가 여기에 있었습니다. 테스트코드의 테스트를 위해 생성해놓은 문서는 상대적으로 너무나도 적은 양의 데이터이기 때문에 IDF 의 값이 대부분 동일하고 TF 값으로 대부분 유사도가 정해질거예요. 반면, 테스트코드에 비해 방대한 품목 데이터가 있는 실제 환경에선 곤약과 스위트콘처럼 IDF 의 차이가 클 수 있습니다.
IDF 가 유의미한 결과를 내주기 위해서는 전체 문서가 모두 한 유통사의 품목으로, 품목명의 구조나 맥락이 동일해야 할 것 같은데요. 하지만 유통사마다 품목명이 모두 제각각인데도 IDF가 모든 유통사의 데이터를 포함한 전체 품목 데이터를 기준으로 계산되면서 오히려 유사도 계산에 역효과를 내고 있었습니다. 또한, 실제환경과 로컬 환경에서의 테스트 결과가 보장되지 않아 문제 재현 및 원인 파악이 어려워보였습니다.
따라서, IDF 를 제외하고 score 계산하는 방법을 알아봤습니다.
IDF를 제외한 점수 계산을 위해 크게 세 가지 방법을 검토해봤습니다.
1. 점수 고정 (Constant Score)
첫번째 방법은 아래와 같이 쿼리에 boost 값을 명시하여 점수를 고정 시키는 Constant Score Query 를 활용한 방법입니다.
{
"query":{
"bool":{
"must":[
{
"bool":{
"should":[
{
"constant_score":{
"filter":{
"wildcard":{
"name.wildcard":{
"wildcard":"*스위트곤*"
}
}
},
"boost":100.0
}
},
{
"constant_score":{
"filter":{
"match":{
"name":"스위트곤"
}
},
"boost":3.0
}
},
{
"constant_score":{
"filter":{
"match":{
"name.ngram":"스위트곤"
}
},
"boost":4.0
}
}
// .. 생략
]
}
}
]
}
}
}
결과를 봤을 때, Boost 만으로 Scoring 되기 때문에 같은 필드에서 검색된 품목은 동일한 점수를 가지는 것을 확인했습니다.
예를 들어 name.ngram 로 검색된 품목들은 모두 Boost 4 인 동일한 점수로 정렬이 제대로 되지 않았습니다.
결론적으로, 이 방식은 유사도 기반 정렬이 필요한 우리의 요구사항에 적합하지 않았습니다.
2. 유사도 모델 변경
기본적으로 ES는 Boost * IDF * TF 식을 사용하는 BM25(Best Matching 25) 모델을 사용합니다. 이를 대신해 DFR(Deviation From Randomness) 모델을 사용해 보았습니다.
DFR 은 현 document에 얼마나 드물게 등장하는지, 문서 길이에 따라 통계적 랜덤성 기반으로 검색됩니다. type 뿐만 아니라 아래처럼 옵션에 가중치나 옵션을 설정해줄수있습니다.
아래는 DFR 모델 설정 예시입니다.
{
"settings": {
"similarity": {
"custom_similarity": {
"type": "DFR",
"basic_model": "g", // 문서 내에 특정 용어가 얼마나 드물게 발생하는지
"after_effect": "b", // 검색어가 얼마나 여러번 등장하는지
"normalization": "h2" // 문서 길이에 따라 빈도 설정
}
}
}
}
보시다시피 DFR 모델에 대한 지식이 없으면 유지보수가 무척 어려워보입니다. 문제가 생기거나 개선의 여지가 생겼을 때 더 복잡한 계산식을 사용하는 모델이기 때문에 쉽게 커스텀하기가 힘들어보이고, 모델의 대한 이해뿐만 아니라 옵션에 대한 각 알고리즘도 알아야하기 때문에 유지보수가 정말 쉽지 않을거라 생각이 들었죠.
우리 팀에 검색 엔진에 대한 전문적인 지식을 가진 분이 없었기 때문에 더 복잡한 모델로 변경하는건 과감하게 제외했습니다.
3. Scripted Similarity 사용
IDF를 제외하고 직접 계산식을 정의하는 방법입니다. 아래는 Scripted Similarity 설정 예시입니다.
{
"setting":{
"similarity":{
"scripted_no_idf":{
"type":"scripted",
"script":{
"source":"double tf = Math.sqrt(doc.freq); return query.boost * tf;"
}
}
}
}
}
위처럼 setting 을 변경하고 쿼리의 explain 을 해보면 script 에 있는 식이 아래와 같이 idOrCode에 들어가 scoring 되는것을 볼 수 있어요.
Explain 결과
{
// .. 생략
"description":"sum of:",
"details":[
{
"details":[
{
"description":"score from ScriptedSimilarity(weightScript=[null], script=[Script{type=inline, lang='painless', idOrCode='double tf = Math.sqrt(doc.freq); return query.boost * tf;', options={}, params={}}]) computed from:",
"details":[
// .. 생략
],
"value":8
}
]
}
// .. 생략
]
}
위 세가지 방법 중 가장 마지막 방법인 Scripted Similarity 로 계산식을 넣기로 했어요. Scripted Similarity 를 선택한 이유는 다음과 같습니다.
- 유연한 계산식 사용
- 계산식을 직접 조정 가능
- 기존 BM25 모델에서 IDF만 제거할 수 있는 계산식을 직접 부여 가능
- 유지보수 용이성
- 계산식이 명확히 노출되어 있어 비교적 수정이 간단
- 쿼리와 독립적
- 점수 계산이 쿼리와 독립적으로 이루어져 다른 쿼리 추가 시에도 영향을 받지 않음
Scripted Similarity 계산식 결정
그후에는 Scripted Similarity 에 적용할 계산식 결정이 필요했습니다.
후보 1. 단순한 TF 계산식
double tf = Math.sqrt(doc.freq);
return query.boost * tf;
/* freq : 문서 내의 토큰 등장 수 */
후보 2. BM 모델과 동일한 TF 계산식
double freq = doc.freq;
double k1 = 1.2;
double b = 0.75;
double dl = doc.length;
double avgdl = 7;
double tf = freq / (freq + k1 * (1 - b + b * dl / avgdl));
return query.boost * tf;
/*
freq : 문서 내의 토큰 등장 수
k1: TF 영향도 가중치
b : 문서 길이 보정 파라미터
dl : 문서 길이
avgdl : 전체 문서의 문서 길이 평균값
*/
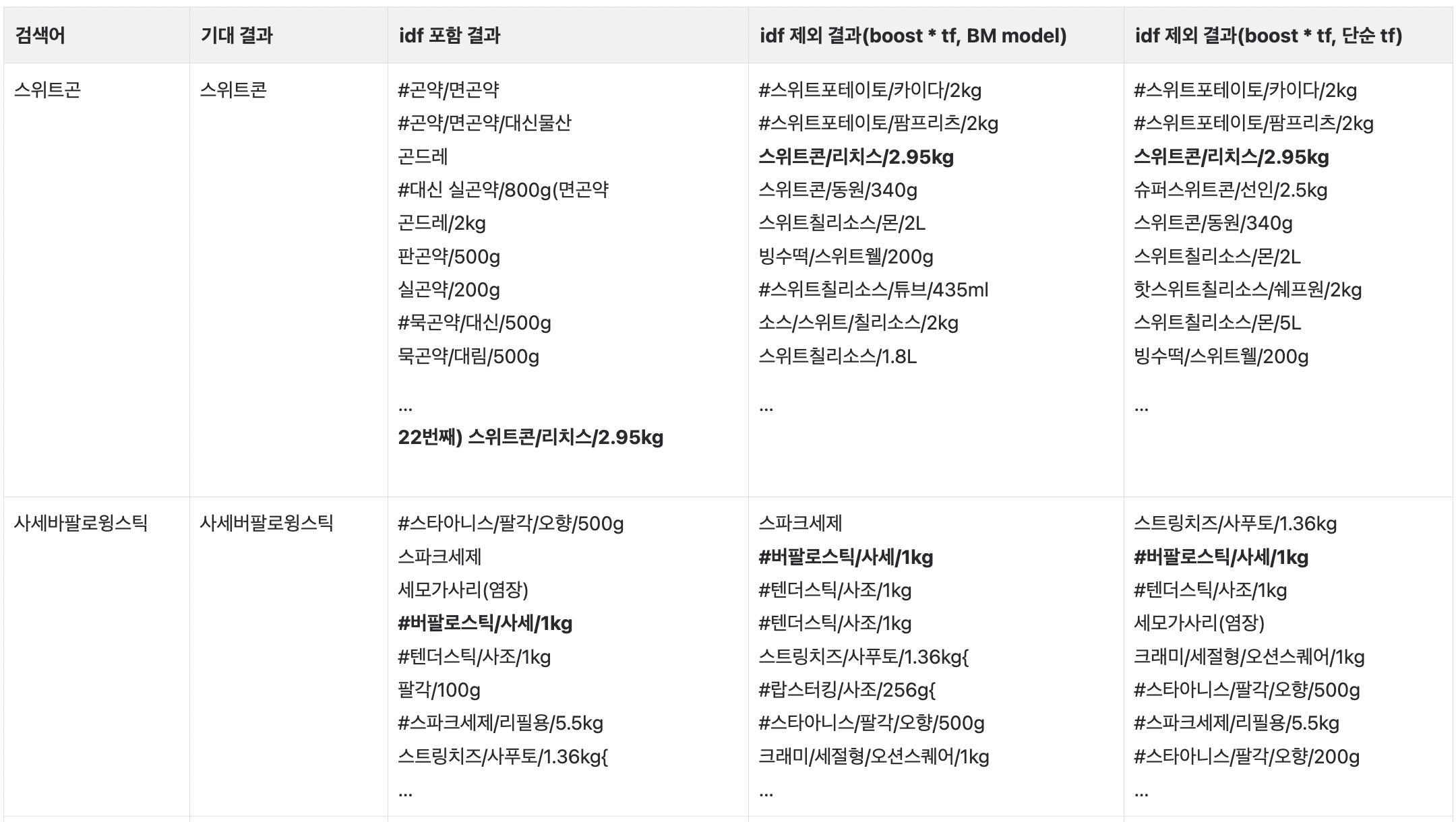
 결과만 보았을 때 확실히 IDF 를 포함했을 때보다 IDF 를 제외했을 때 결과가 개선되긴 했지만, 여전히 단순 TF 계산식, BM 모델 계산식의 결과는 크게 차이가 없었습니다.
결과만 보았을 때 확실히 IDF 를 포함했을 때보다 IDF 를 제외했을 때 결과가 개선되긴 했지만, 여전히 단순 TF 계산식, BM 모델 계산식의 결과는 크게 차이가 없었습니다.
하지만 위 결과의 정렬은 비슷한듯 하지만 실제 점수는 다릅니다. 단순 TF 의 경우 문서 내의 토큰 등장 수로만 TF 를 계산하기 때문에 동일한 점수를 가진 결과가 다수 나타나 매번 정렬이 달라질 수 있습니다.
국산쌀와 찰떡(쌀 국산)는 단순 TF 계산식에 의하면 둘은 동일한 점수를 반환하게 됩니다.
반면 BM 모델과 동일한 TF 계산식의 경우, 문서 내 토큰 등장 수와 문서 길이를 함께 고려하기 때문에 저희가 흔히 생각한대로 국산쌀의 유사도가 더 높은 결과로 나오게 됩니다.
따라서, BM 모델에서 IDF 만 제거한, 후보2 계산식을 사용하기로 결정하였습니다.
다만, avgdl 를 현재의 기준으로 7로 고정시켜 가중치를 조정했지만 이후 문서의 평균 길이가 변경될 경우엔 유지보수가 필요한 부분이 있을 수 있습니다.
하지만 avgdl 가 크게 변하지 않을 것이라는 가정과 점수 계산에 크게 영향을 주지 않는다고 생각해 고정된 계산식으로 가게 되었습니다.
그럼에도 이후에 유지보수가 필요하거나 변경이 필요할 수 있습니다. 꽤 해석이 필요한 계산식을 가지고 있기 때문에 어떤 계기로 IDF를 제거하게 되었는지, Scripted Similarity 를 왜 적용하게 되었는지, 계산식은 어떻게 결정되었고 어떤 의미인지를 자세히 문서화하도록 노력하였습니다.
결과
결과적으로, 아래와 같은 구조를 갖게 되었습니다.
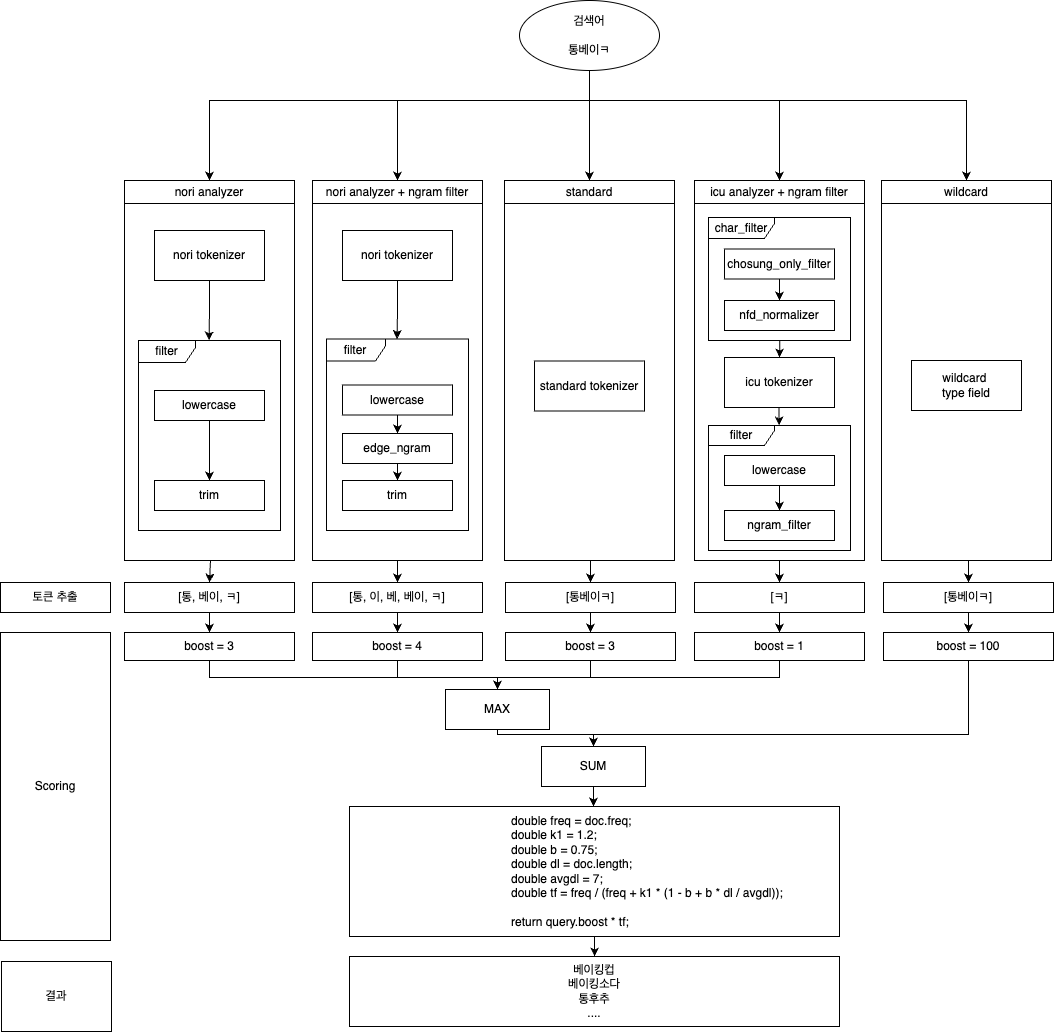
이러한 구조를 통해 현재 검색 정확도는 어떨까요?
아래는 매장 사이드 관련 데이터입니다.
- 2025년 1월 기준
- 검색 결과 성공률: 검색 시 하나 이상의 품목이 결과에 노출되는 경우 → 98.6%
- 검색 목적 달성률: 검색한 품목을 선택한 후, 실제 액션(주문 등)을 수행하는 경우 → 73.6%
이를 통해 상당히 높은 검색 정확도와 달성률을 기록하고 있음을 확인할 수 있습니다.
또한, 아래는 유통사에서 매장의 주문서를 생성할 때, ES 검색이 매우 편리했다는 피드백을 받은 메시지입니다. 키친보드의 검색 기능이 타 ERP와 달리 오타가 있어도 품목을 정확하게 검색할 수 있어 큰 편리함을 느꼈다고 합니다!
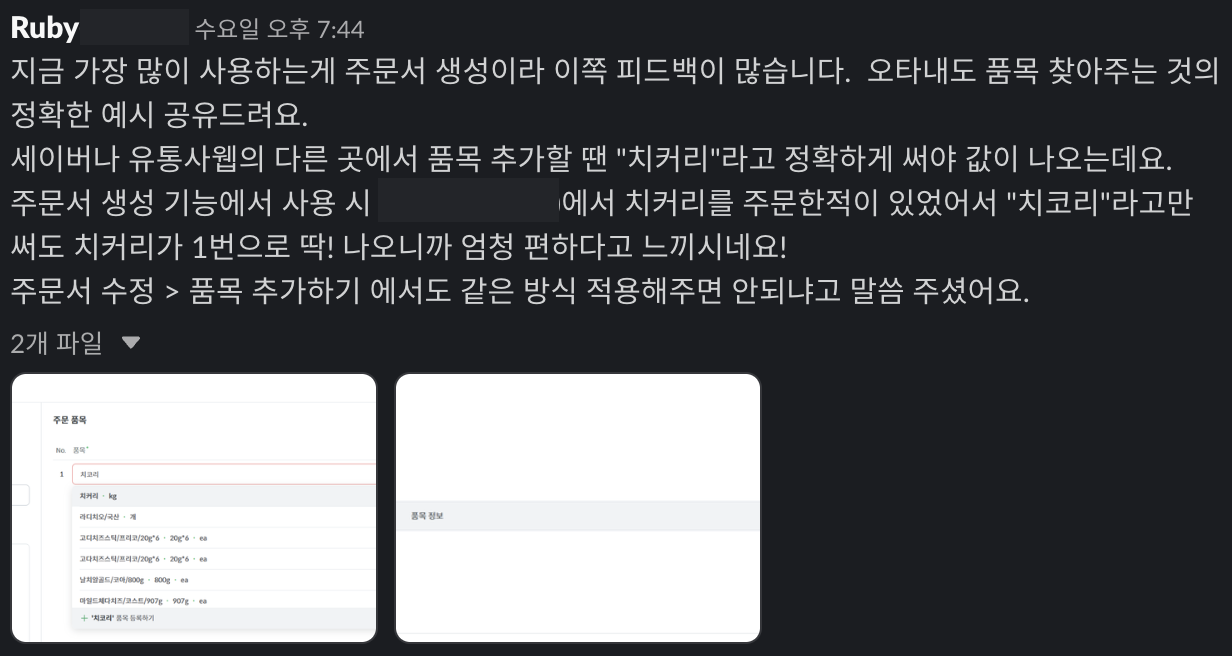
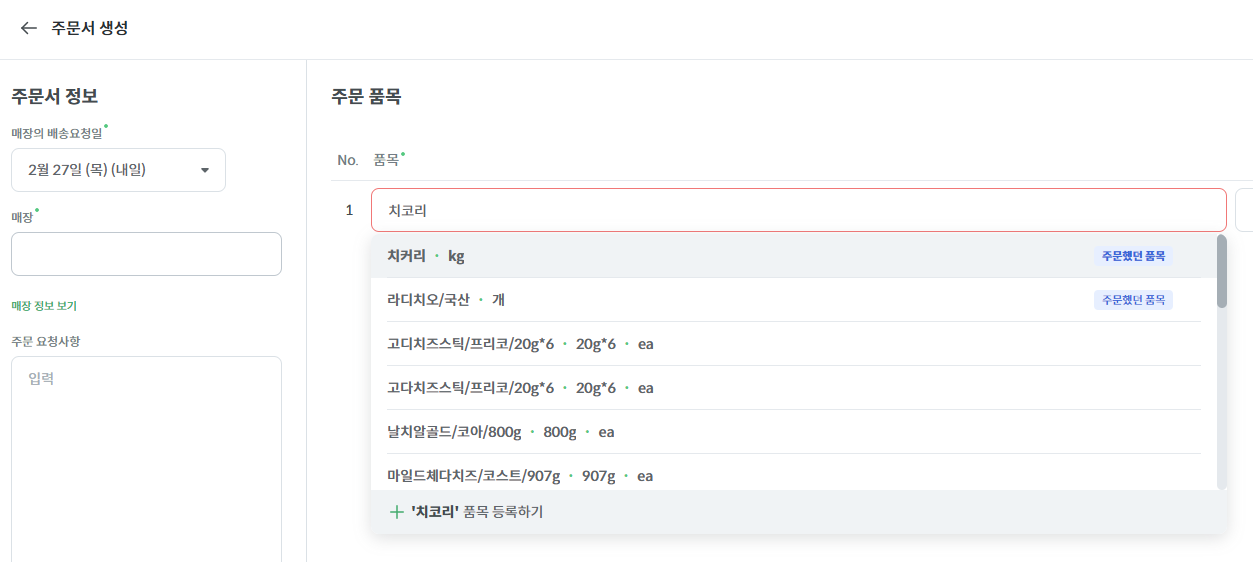
개발 과정에서 어려움이 있었지만 결국 사용자한테 좋은 영향을 주는 기능을 개발한거 같아 아주 뿌듯하네요!
소소한 Tip
중단 시간을 줄인 Reindexing
ES 의 비용을 최소화하기 위해서 최소한의 리소스로 구동하고 있습니다. 그러다보니 인덱스에 새로운 필드가 추가되거나 설정이 변경되는 개선이 될때마다 인덱스를 새롭게 동기화해야하기 때문에 중단이 불가피했는데요. 하지만 주문에서의 검색은 점주들이 꼭 해야만하는 중요한 기능이기 때문에 중단을 최소화하고 싶었습니다.
알아보던 중 찾아낸 것은 별칭(Alias)를 이용한 배포입니다.
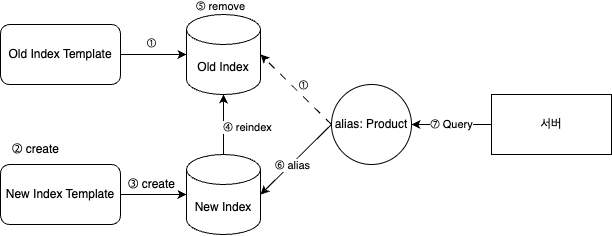
Old Index Template을 템플릿으로 하여 생성된Old Index(별칭:Product) 가 존재한다.- 새로운 매핑 정보가 있는
New Index Template을 생성한다. New Index Template을 템플릿으로 하여New Index를 생성한다.Old Index의 문서를New Index로 reindex 한다.Old Index를 삭제한다.New Index에Productalias 를 부여 한다.- 서버에서 alias 기준으로 쿼리한다.
이렇게 되면 5번과 6번 사이, Product 를 가진 인덱스가 존재하지 않을 시에만 검색 중단이 발생하게 됩니다.
이 방법이 가장 좋은 방법이라고 표현하기는 어렵지만 기존 20만개의 품목을 마이그레이션 하느라 10분이 넘는 중단 시간을 3초 정도의 중단 시간으로 낮출 수 있는 방법이었습니다.
대량 데이터 조회
DB 의 품목 데이터와 ES 인덱스 동기화를 위해 하루에 한번씩 스케줄러가 실행됩니다.
DB 품목 데이터가 삭제될 때 ES 데이터도 삭제되어야 하는데 어떠한 이유로 삭제되지 않는 경우가 있었습니다. 즉, 품목이 DB 데이터엔 없지만 ES 데이터에는 있는 경우죠.
스케줄러에서 전체 ES 인덱스 문서를 조회하고 DB 에 없으면 문서를 삭제해서 동기화해주려고 해요.
다만 전체 문서를 조회하는 과정의 부하가 많이 걱정되긴 했는데요. 그래서 처음엔 페이징을 활용했습니다.
fun deleteOrphanDocuments() {
val pageSize = 1000
var pageable = PageRequest.of(0, pageSize, Sort.by(Sort.Order.asc("id.keyword")))
do {
val indexPage = productIndexRepository.findAll(pageable)
val documentProductIds = indexPage.content.map { it.id }
val dbProductIds = productRepository.findAllById(documentProductIds).map { it.id }
val documentIdsNotInDB = documentProductIds - dbProductIds
productIndexRepository.deleteAllById(documentIdsNotInDB)
pageable = pageable.next()
} while (indexPage.hasNext())
}
ES야.. 죽지마.. 테스트서버에서 확인해보니 동기화 할 때마다 자꾸 ES 서버가 다운되더라고요.. 페이징보다 Scroll API 를 이용하는 것이 훨씬 성능상 좋다고 하여서 Scroll API 를 적용해봤습니다.
fun deleteOrphanDocuments() {
val toDeleteProductIds = mutableListOf<UUID>()
val batchSize = 1000
var documentIdsWithScroll = productIndexRepository.findAllIdWithScroll(size = batchSize)
while (documentIdsWithScroll.productDocumentIds.isNotEmpty()) {
val documentIds = documentIdsWithScroll.productDocumentIds
val dbProductIds = productRepository.findAllById(documentIds).map { it.id }
toDeleteProductIds.addAll(documentIds - dbProductIds)
documentIdsWithScroll =
productIndexRepository.findAllIdByScrollId(
scrollId = documentIdsWithScroll.nextScrollId,
)
}
productIndexRepository.clearScroll(documentIdsWithScroll.nextScrollId)
productIndexRepository.deleteAllById(toDeleteProductIds)
}
ES 에서 Scroll 을 생성할 때 설정한 시간만큼 Scroll 정보를 저장하고 있고 해당 Scroll ID 를 가지고 다음 데이터를 처리단위만큼 반환해줍니다. 받은 데이터엔 또 다음 Scroll 조회를 위한 Scroll ID 를 반환하는 형식입니다.
장점은 페이징 조회보다 계산과 조회가 빠르고 부하가 적은 것인데요. 다만, Scroll 정보를 저장하고 있어야한다는 단점이 있습니다.
조회 후 clearScroll 해주고 만료 시간을 적게 설정하면 큰 문제가 되지 않을거예요.
변경 후엔 ES가 건강해졌습니다. 대량 조회가 필요할 땐 Scroll API 를 사용하는걸 추천드립니다.
검색 품질 유지하기
추가적으로 쿼리나 스코어링 방식을 변경하다보면 현재의 요구사항에는 만족했지만 이전의 요구사항에 반할 때가 생길 수 있습니다. 그래서 테스트코드에 이전 요구사항에 관련된 테스트케이스를 꼭 남겨두고 현재 만족할 수 있는 테스트케이스를 더해서 이전과 현재 요구사항을 모두 만족할 수 있도록 구현하는걸 목표로 했습니다.
특정 케이스에 모두 만족하는지 일일이 확인하는 것은 현실적으로 어려울 수 있으니 테스트를 든든하게! 잘 짜두는 것이 많은 도움이 될 겁니다!
이후엔 어떤 것을 할 것인가
Wildcard 검색, 초성 검색, IDF 제거 등 여러 개선들을 해왔는데요. 요구사항에 맞게, 문제상황에 맞게 조치하는 형식으로 개선해나가다보니 조금은 불필요한 옵션들로 검색을 무겁게 만든 부분들이 분명 있을 수 있을것 같아요. 또한 검색 엔진에 대한 전문적인 지식 없이 점차 학습하여 개발하다보니 초반과 후반에 대한 지식의 차이가 커서 초반에 했던 방법들이 논리보단 여러 검색어 테스트 POC 로 적용한 것들이 많아요. 그래서 조금 뚱뚱해진 ES 의 다이어트가 필요해보입니다.
일단 생각나는 것은 부하를 줄 수 있는 Wildcard 를 없애는 것인데요. N-gram 과 Tokenizer 의 적절한 조합으로 Wildcard 없이 포함된 단어가 잘 조회될 수 있도록 방법을 찾아봐야할 것 같아요.
그리고 이젠 품목 데이터가 많이 쌓여서 한국 식자재의 대부분 데이터가 존재할 것인데요. 이 데이터로 사용자 사전을 만들어서 검색의 정확도를 높이는 작업을 해볼 수 있을 겁니다. 추가되는 데이터에 맞춰 사전이 관리되어야 하기 때문에 개발자뿐만 아니라 타부서 팀원분들도 쉽게 관리하기 위한 시스템을 마련해야 할 것 같습니다.
외래어를 포함하는 새로운 식자재를 등록하는 것도 중요하지만 “셀러드”처럼 식자재이지만 표기를 잘못한 경우도 있어서 이런 경우엔 품목명 자체의 수정이 필요합니다. ERP에 등록된 품목명과 키친보드의 등록된 품목명의 강한 결합성을 끊을 수 있도록, 검색 엔진의 설정뿐만 아니라 키친보드 품목명의 데이터 클렌징이 필요할거예요.
마무리
끝으로, 저희의 지금 검색 엔진은 완성이 아닙니다. 지금도 많이 부족할 수 있지만 사용자의 보이스를 들으며 꾸준히 발전하고 있습니다. 키친보드를 사용하는 점주 모두가 검색이 너무 편해요! 라고 할때까지, 대충 검색해도 마음속으로 생각했던 품목이 결과에 나오는 그날까지, 발전은 계속 됩니다!
ES 도입과 설정에 도움주시고 자기 일처럼 고민해주신 백엔드 개발자분들과 개선을 위한 데이터를 제공해주신 데이터팀분들, 검색 개선을 위해 피드백 주신 사업팀분들 모두 감사합니다!

스포카에서는 “식자재 시장을 디지털화한다” 라는 슬로건 아래, 매장과 식자재 유통사에 도움되는 여러 솔루션들을 개발하고 있습니다.
더 나은 제품으로 세상을 바꾸는 성장의 과정에 동참 하실 분들은 채용 정보 페이지를 확인해주세요!