
안녕하세요. 키친보드 팀의 백엔드 프로그래머 남경호입니다.
최근 Kotlin이 서버 언어로 주목받기 시작하면서 Kotlin + Spring으로 서버를 개발하는 케이스가 많아졌습니다. 그러면서 자연스레 Kotlin으로 JPA를 사용하는 사례 또한 많아졌는데요. 다만 Kotlin으로 JPA를 사용하다 보면, 정확하게는 Entity를 정의하다 보면 Kotlin의 언어적 특성과 잘 맞지 않는 부분을 많이 발견하게 됩니다. JPA 는 Java Persistence API의 약자로 Java 진영의 ORM 표준을 말합니다. 그래서 데이터베이스를 매핑해주는 Entity를 정의할 때 Java를 기준으로 Entity를 정의하기 쉽게 만들어져 있기 때문입니다.
이 글은 스포카에서 Kotlin으로 JPA Entity를 보다 Entity 답게 사용하기 위해 고민한 내용을 담은 것입니다. 그동안 Kotlin을 사용하면서 Java로 Entity를 정의했을 때의 차이와 최대한 Entity의 컨셉을 해치지 않으면서 어떻게 Kotlin답게 작성하면 좋을지 고민한 것들을 적어보려고 합니다.
문제상황
Kotlin + JPA를 소개하는 블로그나 영상들을 보면 Entity를 정의한 부분에서 아쉬운 코드들을 많이 볼 수 있습니다. 물론 주제가 Entity를 좀 더 객체 지향적으로 정의하는 것이 아니라 Java보다 Kotlin으로 JPA를 사용했을 때 장점을 소개하는 것에 초점이 맞춰져 있다 보니 그러리라 생각이 듭니다. 하지만 저는 ORM에서 가장 중요한 것은 도메인 모델인 Entity라 생각합니다. 비즈니스 로직이 가장 풍부해야 하며 도메인이 가진 특징을 가장 잘 표현해줄 수 있어야 합니다. 그래서 Entity를 정의할 때 JPA의 규격을 위반하지 않으면서 Kotlin이 추구하는 개발 철학에 맞게 작성하면 좋다고 생각합니다.
그럼 제가 생각하는 안티 패턴 사례를 좀 더 자세히 살펴보겠습니다.
무분별한 mutable property 사용
Kotlin은 불변(immutable)을 지향합니다. 변수(mutable)는 부작용이 많기 때문이지요. 앞서 말했다 시피 JPA는 java에 맞게 ORM을 사용하기 위한 API를 제공해줍니다. 그래서 기본적으로 mutable property에 초점이 맞춰져 있습니다. 사실 Entity가 가진 특성을 살펴보면 JPA가 java의 특성에 맞게 mutable property를 사용하는 것이 아니라 Entity의 특성에 따라 mutable property를 사용한 것이 맞는다는 생각이 듭니다. (Entity에 대한 글 을 참고해 주세요)
아무튼 그래서 Kotlin으로 Entity를 정의했음에도 불구하고 아래와 같은 코드를 쉽게 접할 수 있습니다.
@Entity
class Person(
@ID
var id: Long,
@Column
var name: String,
@Column
var age: Int,
)
위 코드의 문제점은 무엇일까요? 바로 캡슐화가 되어있지 않다는 것입니다. 그래서 Entity가 가진 상태를 그대로 노출하는 것은 차치하고 그 상태를 외부에서 아무런 제약 없이 변경할 수 있습니다. 심지어 Entity에서 바꾸지 말아야 할 식별자까지 바꿀 수 있도록 정의한 것은 정말 치명적입니다.
다만 Kotlin에서 클래스가 가진 상태는 field가 아니라 property입니다. (Kotlin 공식 문서 를 참고해 주세요) 즉, 아래 Java 코드와 같이 field를 그대로 노출한 코드와 위 Kotlin 코드와는 차이가 있습니다.
@Entity
class Person {
@ID
long id;
@Column
String name;
@Column
int age;
public Foo(long id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
}
왜냐하면 Property는 Field를 외부에 직접 노출하지 않고 Setter와 Getter를 통해 노출하는 것이기 때문입니다. 만약 위 Java 코드에 Field를 그대로 노출하지 않고 Property로 노출하도록 하면 아래와 같이 적어볼 수 있겠습니다.
@Entity
public class Foo {
@ID
private long id;
@Column
private String name;
@Column
private int age;
public Foo(long id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public void setId(long id) {
this.id = id;
}
public long getId() {
return id;
}
public void setName(String name) {
this.name = name;
}
public String getNmae() {
return name;
}
public void setAge(int age) {
this.age = age;
}
public int getAge() {
return age;
}
}
다시 주제로 돌아와서 저는 Field로 노출하든 Property로 노출하든 Entity가 가진 내부 상태의 변경을 직접 노출하도록 정의하는 것은 좋지 못하다고 생각합니다.
내부 상태를 변경하는 것은 특정 행위를 통해 이루어집니다. foo.age = 3 또는 foo.setAge(3)와 같은 코드는 Entity의 상태를 바꾸는 목적을 표현해주지 못합니다. 차라리 foo.age의 Setter는 외부에 노출하지 않고 foo.getOld()와 같이 표현하는 게 더 나을 것입니다.
Data class 활용
다음으로 가장 많이 발견되는 사례는 바로 Data class를 이용한 Entity를 정의하는 사례입니다. Kotlin의 Data class 는 데이터를 전달하기 위한 용도로 사용하는 것을 목적으로 만들어진 클래스입니다. 데이터를 전달하는 구조체는 사용자가 전달한 데이터의 원본을 유지하는 것이 중요합니다. 그래서 저는 Data class를 사용할 때 꼭 필요한 경우가 아니라면 불변변수(immutable)를 사용합니다. 앞서 Entity에 대한 글 을 보았다면 알 수 있겠지만 Entity는 식별자 외에는 생명주기 동안 상태가 변경될 수 있습니다. 그리고 Entity는 특정 생명주기를 가지고 비즈니스 요구사항을 수행하는 객체이므로 단순히 데이터를 전달하기 위한 용도로 사용하는 Data class와는 성격이 다르다고 볼 수 있습니다. 오히려 Value Object와 유사한 성격을 가진다고 볼 수 있습니다. (Value Object에 대한 글을 참고해 주세요)
그러면 왜 사람들은 Data class를 사용할까요? 매개변수가 없는 생성자를 사용하지 못한다는 제약조건이 있음에도 말입니다. 아마 Data class가 copy와 equals, hashCode, toString을 기본으로 제공해주기 때문이지 않겠느냐고 조심스럽게 예상해봅니다. 아니라면 Entity를 단순히 DB 테이블의 상태를 전달해주는 객체로 본다는 것인데, 요즘 많은 블로그나 영상을 통해 기존에 사용하던 Entity가 도메인 모델이 아닌 Object Mapper로써의 역할만 하도록 정의하는 방식이 좋지 않다는 것을 배워가고 있기 때문에 Kotlin으로 JPA를 사용하고 있는 개발자라면 전자의 이유가 클 것이라는 게 제 생각입니다. 하지만 Kotlin Data class를 소개하는 문서에서 보면 아래와 같은 문구를 볼 수 있습니다.
The compiler automatically derives the following members from all properties declared in the primary constructor
즉, 기본 생성자에 정의한 Property 들만 copy와 equals, hashCode, toString함수들에 활용된다는 것입니다. 그래서 아래와 같이 Data class를 정의하고 equals를 호출하면 예상치 못한 결과를 볼 수 있습니다.
data class Person(val name: String) {
var age: Int = 0
}
val person1 = Person("John")
val person2 = Person("John")
person1.age = 10
person2.age = 20
person1 == person2 // true
위와 같은 상황을 피하기 위해서는 기본생성자에 모든 Property를 정의해야 합니다. 하지만 Entity를 생성할 때 모든 상태를 생성자 매개변수로 받는 것이 과연 좋은 디자인일까요? 저는 꼭 필요한 매개변수로 받고 필요한 상태는 Entity 내부에서 기본값으로 정의하도록 하는 게 좋다고 생각합니다.
아래와 같이 주문 상태를 가진 주문 Entity를 정의한다고 가정해 보겠습니다. Data class로 정의한다면 아래와 같이 정의할 수 있을 것입니다.
@Entity
data class Order(
@Id
val id: UUID,
@Column
val orderAt: LocalDateTime,
@Column
val state: OrderState,
)
만약 주문서가 최초 생성될 때 주문상태가 SUBMITTED 상태로 해야 한다면 어떻게 할 수 있을까요? 아마 아래와 같이 사용하는 코드에서 매개변수로 넣어주거나 기본값을 주려고 할 것입니다.
@Entity
data class Order(
@Id
val id: UUID,
@Column
val orderAt: LocalDateTime,
@Column
val state: OrderState = OrderState.SUBMITTED,
)
Order(
id = UUID.randomUUID(),
orderAt = LocalDateTime.now(),
state = OrderState.SUBMITTED,
)
하지만 만약에 사용자가 주문을 생성할 때 상태를 SUBMITTED가 아닌 다른 값으로 넣는다면 어떨까요? 위와 같은 방법으로는 이와 같은 사용을 막을 방법이 없을 것입니다.
Order(
id = UUID.randomUUID(),
orderAt = LocalDateTime.now(),
state = OrderState.CANCELED,
)
그래서 아래와 같이 생성자 매개변수로 두지 않고 Entity가 생성될 때 기본값을 가지도록 할 수 있습니다. 하지만 이렇게 정의한다면 앞서 보여준 사례처럼 copy와 equals, hashCode, toString 함수들을 원하는 대로 활용할 수 없게 됩니다. 결국 Data class를 활용하는 것보다 일반 클래스를 사용하는 것이 더욱 자유로운 설계를 할 수 있습니다.
@Entity
data class Order(
@Id
val id: UUID,
@Column
val orderAt: LocalDateTime,
) {
@Column
val state: OrderState = OrderState.SUBMITTED
}
Order(
id = UUID.randomUUID(),
orderAt = LocalDateTime.now(),
)
한편 Entity의 동등성을 Data class의 equqls와 같이 모든 Property에 대한 비교를 통해 보장해야 할까요? 다시 Entity에 대한 글 을 보면 Entity에 대한 동일성은 오로지 식별자를 통해서 이루어진다는 것을 알 수 있습니다. 즉 생명주기 동안 Person이라는 A Entity는 언제든지 이름 또는 나이가 바뀔 수 있습니다. 이름이나 나이가 바뀌었다고 해서 A Entity가 다른 Entity가 될 수 없는 것입니다.
Kotlin에서 Java와 같이 equals를 따로 재정의하지 않으면 참조 비교를 통해 동일성을 확인합니다. 그래서 만약 프로그램에서 동일한 식별자를 가진 A Entity를 다른 코드에서 조회(좀 더 자세히 말하자면 영속화된 데이터를 메모리로 불러온 경우)하여 동일한 Entity인지 비교한다면 동일하다고 판단하지 않을 수 있습니다. 같은 식별자를 가진 Entity는 동일한 객체라고 판단해야 하므로 아래와 같이 equals와 hashCode를 재정의해주어야 합니다.
class Person {
override fun equals(other: Any?): Boolean {
if (other == null) {
return false
}
if (this::class != other::class) {
return false
}
return id == (other as Person).id
}
override fun hashCode() = Objects.hashCode(id)
}
lateinit 사용
다음은 연관관계 정의 시 lateinit을 사용하는 경우입니다. Kotlin에서 lateinit을 통해 초기화를 뒤로 미룰 수 있는 코드를 작성할 수 있습니다. 주로 초기화에 비용이 많이 발생하는 경우 코드를 사용하는 시점까지 초기화를 미루어 꼭 필요한 경우에 초기화를 해 성능향상 및 자원 효율성에 도움을 주려는 용도로 사용합니다.
Kotlin에서는 Java와 달리 초기화를 하지 않고 Property를 정의할 수 없습니다.
@Entity
class Person {
@Id
val id: UUID // compile error: Property must be initialized or be abstract
@Column
val name: String // compile error: Property must be initialized or be abstract
}
그래서 아래와 같이 생성자 매개변수로 전달받거나 기본값을 넣어줘야 합니다.
@Entity
class Person(
id: UUID,
name: String,
) {
@Id
val id: UUID = id
@Column
val name: String = name
}
@Entity
class Person {
@Id
val id: UUID = UUID.randomUUID()
@Column
val name: String = ""
}
일반적으로 Kotlin으로 JPA Entity를 정의할 때 Column만 존재하는 경우 lateinit을 사용하는 경우는 거의 없습니다. 위와 같이 생성자 매개변수를 활용하거나 기본값을 넣어주기 때문이죠. 문제는 연관관계를 정의할 때입니다. 이는 Java에서 JPA를 사용할 때 사용하던 패턴을 그대로 가져오다 보니 생긴 안 좋은 패턴이지 않나 생각됩니다. 사용사례를 한번 살펴보겠습니다.
사용자가 게시판을 작성하는 기능을 만든다고 가정해보겠습니다. 하나의 사용자는 여러 게시판을 작성할 수 있고 게시판은 작성자 정보를 저장합니다. 이 기능을 구현하기 위해 Java로 Entity를 아래와 같이 정의해보겠습니다.
@Entity
public class Board {
@Id
@GeneratedValue
private UUID id;
@Column
private String title;
@Column
private UUID writerId;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "writerId")
private User writer;
public Board(String title, UUID writerId) {
this.title = title;
this.writerId = writerId;
}
// 생략...
}
생성자를 보면 writerId는 초기화해주지만 writer는 초기화해 주지 않는 것을 볼 수 있습니다. 하지만 Java는 이렇게 사용해도 컴파일 시 오류가 발생하지 않습니다. 기본적으로 초기화해주지 않으면 null 값을 가지기 때문이죠. Kotlin으로 위 Entity를 다시 정의해 보겠습니다.
@Entity
class Board(
title: String,
writerId: UUID,
) {
@Id
var id: UUID = UUID.randomUUID()
@Column
var title: String = title
@Column
var writerId: UUID = writer.id
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "writerId")
lateinit var writer: User
}
이렇듯 연관관계를 정의할 때 lateinit을 활용하는 경우를 많이 볼 수 있습니다. 컴파일도 잘되기 때문에 아무 문제가 없어 보입니다. 심지어 아래와 같이 조회기능을 만들어 사용해보면 정상적으로 User가 조회됩니다.
@DataJpaTest(showSql = true)
class BoardRepositoryTest {
@Autowired lateinit var testEntityManager: TestEntityManager
@Autowired lateinit var boardRepository: BoardRepository
@Test
fun test_get_writer() {
// Given
val user = User("홍길동")
val board = Board("게시판", user.id)
testEntityManager.persistAndFlush(user)
testEntityManager.persistAndFlush(board)
testEntityManager.detach(user)
testEntityManager.detach(board)
// When
val actual = board2Repository.getReferenceById(board.id)
// Then
Assertions.assertEquals("홍길동", actual.writer.name)
}
}
SQL 로그를 봐도 우리가 원했던 대로 잘 조회하는 것을 볼 수 있습니다.
Hibernate:
insert
into
"user"
(name, id)
values
(?, ?)
Hibernate:
insert
into
board
(title, writer_id, id)
values
(?, ?, ?)
Hibernate:
select
board0_.id as id1_1_0_,
board0_.title as title2_1_0_,
board0_.writer_id as writer_i3_1_0_
from
board board0_
where
board0_.id=?
Hibernate:
select
user0_.id as id1_5_0_,
user0_.name as name2_5_0_
from
"user" user0_
where
user0_.id=?
그렇다면 잘 동작하는데 무엇이 문제일까요? 문제는 영속화한 데이터를 조회할 때가 아니라 Entity를 생성한 직후 해당 Entity를 다룰 때 발생합니다. 예를 들어 저장을 위해 Entity를 생성하고 난 후 writer를 이용하여 특정한 기능을 수행하기 위해 아래와 같이 writer를 조회해 보겠습니다. 그럼 런타임 오류가 발생합니다.
val user = User("홍길동")
val board = Board2("게시판", user.id)
val writer = board.writer // error: lateinit property writer has not been initialized
왜냐하면 영속화된 Board를 조회할 때는 JPA가 writer를 초기화해주었지만 이제 막 생성한 Entity는 JPA가 writer를 초기화해주지 않았기 때문에 위와 같은 오류가 발생하는 것입니다. 그래서 이처럼 lateinit을 활용하는 것은 시스템이 단순할 땐 어찌어찌 사용할 순 있겠지만 어떻게 해서든 위와 같은 오류를 마주치게 되고 이 오류를 우회하기 위해 억지스러운 코드 구현들이 생겨나는 것입니다.
그렇다면 lateinit을 사용하지 않고 java와 같이 연관관계를 정의하는 다른 방법은 어떤 것이 있을까요? 간단합니다. nullable 타입으로 정의하는 것이죠. 조금만 생각해보면 이게 맞는 게 java의 변수는 초기화하지 않으면 기본값이 null입니다. 그러므로 초기화하지 않은 Property는 null로 보는 것이 맞는다고 봅니다.
@Entity
class Board(
title: String,
writerId: UUID,
) {
@Id
var id: UUID = UUID.randomUUID()
@Column
var title: String = title
@Column
var writerId: UUID = writer.id
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "writerId")
var writer: User? = null
}
위와 같이 코드를 변경해도 잘 동작합니다.
@DataJpaTest(showSql = true)
class BoardRepositoryTest {
@Autowired lateinit var testEntityManager: TestEntityManager
@Autowired lateinit var boardRepository: BoardRepository
@Test
fun test_get_writer() {
// Given
val user = User("홍길동")
val board = Board("게시판", user.id)
testEntityManager.persistAndFlush(user)
testEntityManager.persistAndFlush(board)
testEntityManager.detach(user)
testEntityManager.detach(board)
// When
val actual = board2Repository.getReferenceById(board.id)
// Then
Assertions.assertEquals("홍길동", actual.writer?.name) // writer는 nullable이기 때문에 `?`를 써줘야한다.
}
}
nullable하게 타입을 정의하면 사용하는 코드에서는 null이 있음을 가정하고 코드를 작성하기 때문에 적어도 예상치 못하게 초기화 오류를 만나지 않을 수는 있습니다.
하지만 이 방법 또한 근본적인 해결책이라 보기 어렵습니다. 비즈니스 요구사항에 따라 다르겠지만 적어도 이 사례에서는 게시판이 생성되었는데 작성자가 없는 것이 말이 안 되기 때문이죠. ORM은 Entity 객체를 데이터베이스에 영속화를 손쉽게 해주기 위한 도구입니다. 그런데 이 ORM의 특성으로 인해 도메인의 제약조건을 위반하는 것이 과면 맞는 것일까요? 저는 아니라고 생각합니다. 그래서 가장 좋은 방법은 게시판을 생성할 때 사용자의 식별자를 넣어주는 것이 아니라 사용자 자체를 넣어주는 것이 맞는다고 생각됩니다. 그렇게 되면 아래와 같이 불필요한 writerId와 같은 Property로 사용하지 않아도 됩니다.
@Entity
class Board(
title: String,
writer: User,
) {
@Id
var id: UUID = UUID.randomUUID()
@Column
var title: String = title
@ManyToOne(fetch = FetchType.LAZY, optional = false)
var writer: User = writer
}
영속화 시 SQL 쿼리를 보면 이전과 동일하게 동작함을 볼 수 있습니다.
Hibernate:
insert
into
"user"
(name, id)
values
(?, ?)
Hibernate:
insert
into
board
(title, writer_id, id)
values
(?, ?, ?)
여러 안티 패턴들이 있지만 제가 생각하기에 가장 많이 발견되는 대표적인 것들만 소개해 보았습니다. 그럼 이제 본론으로 돌아가서 스포카에서 Kotlin으로 JPA Entity를 정의할 때 사용하고 있는 여러 가지 팁을 소개해 보겠습니다. 팁을 소개하기 전에 우리가 개발할 때 흔하게 접할 수 있는 게시판 도메인을 예제로 두고 이야기를 풀어가면 좋을 것 같아서 먼저 도메인을 소개하고 팁을 소개하는 순서로 진행해 보겠습니다.
도메인 정의
앞으로 설명하게 될 Entity를 보다 이해하기 쉽게 설명하기 위해서 우리가 개발을 시작할 때 흔하게 접하는 게시판 도메인을 가상으로 만들어 본다고 가정해 보겠습니다. 사용자는 API를 이용하여 게시판을 생성, 조회, 수정, 삭제할 수 있고 각 게시판에 댓글과 태그 정보를 추가할 수 있습니다. 자세한 유저 스토리는 아래와 같습니다.
유저 스토리
- 사용자는 게시판의 유형과 제목, 내용, 기타정보, 작성자 입력하여 게시판을 생성할 수 있다.
- 사용자는 생성된 게시판의 상세 조회를 통해 게시판의 유형, 제목, 내용, 기타정보, 작성자를 조회할 수 있다.
- 사용자는 생성된 게시판의 제목과 내용, 기타정보를 수정할 수 있다.
- 사용자는 생성된 게시판에 태그를 추가할 수 있다.
- 사용자는 생성된 게시판에 이미 존재하는 태그를 삭제할 수 있다.
- 사용자는 생성된 게시판에 댓글을 추가할 수 있다.
- 사용자는 자신의 게시글을 조회할 수 있다.
- 사용자가 삭제되면 사용자가 작성한 게시글이 모두 삭제된다.
Entity
Entity는 아래와 같습니다. 총 3개의 Entity가 존재하며 사용자와 게시판 그리고 Root Aggregate라고 표현하긴 힘들지만, 단일로 생명주기를 가질 수 있는 Tag가 그 하나입니다. 지금 이 글을 읽고 독자라면 JPA에 대해서 기본적으로 알고 있다는 가정을 하고 있기 때문에 JPA Annotation 관련해서는 별도로 설명하지 않겠습니다. 다소 생략된 부분이 많기 때문에 데이터베이스 스키마가 바로 떠오르지 않는다면 아래 ERD를 참고해주세요.
@MappedSuperclass
abstract class PrimaryKeyEntity : Persistable<UUID> {
@Id
@Column(columnDefinition = "uuid")
private val id: UUID = UlidCreator.getMonotonicUlid().toUuid()
@Transient
private var _isNew = true
override fun getId(): UUID = id
override fun isNew(): Boolean = _isNew
override fun equals(other: Any?): Boolean {
if (other == null) {
return false
}
if (other !is HibernateProxy && this::class != other::class) {
return false
}
return id == getIdentifier(other)
}
private fun getIdentifier(obj: Any): Serializable {
return if (obj is HibernateProxy) {
obj.hibernateLazyInitializer.identifier
} else {
(obj as PrimaryKeyEntity).id
}
}
override fun hashCode() = Objects.hashCode(id)
@PostPersist
@PostLoad
protected fun load() {
_isNew = false
}
}
@Entity
@Table(name = "`user`")
class User(
name: String,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@OneToMany(fetch = FetchType.LAZY, cascade = [CascadeType.ALL], mappedBy = "writer")
protected val mutableBoards: MutableList<Board> = mutableListOf()
val boards: List<Board> get() = mutableBoards.toList()
fun writeBoard(board: Board) {
mutableBoards.add(board)
}
}
@Entity
@Table(uniqueConstraints = [UniqueConstraint(name = "tag_key_value_uk", columnNames = ["`key`", "`value`"])])
class Tag(
key: String,
value: String,
) : PrimaryKeyEntity() {
@Column(name = "`key`", nullable = false)
var key: String = key
protected set
@Column(name = "`value`", nullable = false)
var value: String = value
protected set
}
@Entity
class Board(
title: String,
content: String,
information: BoardInformation,
writer: User,
tags: Set<Tag>,
) : PrimaryKeyEntity() {
@Column(nullable = false)
var createdAt: LocalDateTime = LocalDateTime.now()
protected set
@Column(nullable = false)
var title: String = title
protected set
@Column(nullable = false, length = 3000)
var content: String = content
protected set
@Embedded
var information: BoardInformation = information
protected set
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(nullable = false)
var writer: User = writer
protected set
@ManyToMany(fetch = FetchType.LAZY, cascade = [CascadeType.PERSIST, CascadeType.MERGE])
@JoinTable(
name = "board_tag_assoc",
joinColumns = [JoinColumn(name = "board_id")],
inverseJoinColumns = [JoinColumn(name = "tag_id")],
)
protected val mutableTags: MutableSet<Tag> = tags.toMutableSet()
val tags: Set<Tag> get() = mutableTags.toSet()
@ElementCollection
@CollectionTable(name = "board_comment")
private val mutableComments: MutableList<Comment> = mutableListOf()
val comments: List<Comment> get() = mutableComments.toList()
fun update(data: BoardUpdateData) {
title = data.title
content = data.content
information = data.information
}
fun addTag(tag: Tag) {
mutableTags.add(tag)
}
fun removeTag(tagId: UUID) {
mutableTags.removeIf { it.id == tagId }
}
fun addComment(comment: Comment) {
mutableComments.add(comment)
}
init {
writer.writeBoard(this)
}
}
@Embeddable
data class BoardInformation(
@Column
val link: String?,
@Column(nullable = false)
val rank: Int,
)
@Embeddable
data class Comment(
@Column(length = 3000)
val content: String,
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(nullable = false)
val writer: User,
)
ERD
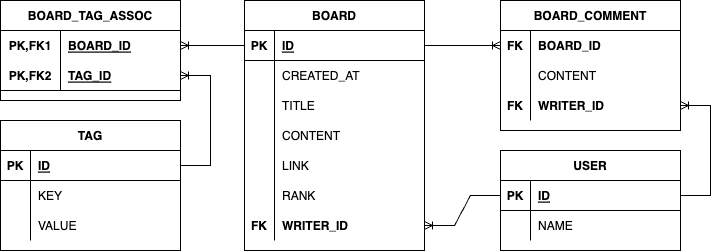
Kotlin Entity 정의 팁
위 예제코드에 저희가 본격적으로 소개하고자 하는 Kotlin에서 JPA Entity를 정의할 때 사용하면 좋을 만한 팁들이 녹아 있습니다. 하나하나 살펴보겠습니다.
allopen
많은 블로그나 영상을 통해서 Kotlin으로 JPA를 사용할 때 Entity에 allopen옵션과 no-args constructor옵션을 주어야 한다는 것은 널리 알려져 있습니다. 그래서 간단하게 언급만 하고 넘어가겠습니다.
Spring Initializr 를 통해 Kotlin으로 JPA 프로젝트를 설정해보았다면 알겠지만 아래 플러그인들이 추가된 것을 볼 수 있습니다.
kotlin("plugin.spring") version "1.7.0"
kotlin("plugin.jpa") version "1.7.0"
Kotlin에서는 Spring plugin 을 통해 스프링의 컴포넌트들을 사용하는 데 문제가 없도록 모든 클래스에 open 키워드를 선언하지 않아도 되도록 All-open plugin을 포함하고 있습니다.
그리고 Jpa plugin 을 통해 JPA 관련 클래스들을 생성하는 데 문제가 없도록 생성자에 매개변수가 없는 No-arg plugin 도 포함해줍니다.
위 설정만으로 JPA를 사용하는 데 문제가 없어 보이지만 막상 Entity를 Decompile 해보면 여전히 final 키워드가 있는 것을 볼 수 있습니다.
public final class com/example/kotlinentitytutorial/User extends com/example/kotlinentitytutorial/PrimaryKeyEntity {
@Ljavax/persistence/Entity;()
@Ljavax/persistence/Table;(name="`user`")
// access flags 0x2
private Ljava/lang/String; name
@Ljavax/persistence/Column;(nullable=false, unique=true)
@Lorg/jetbrains/annotations/NotNull;() // invisible
// access flags 0x11
public final getName()Ljava/lang/String;
@Lorg/jetbrains/annotations/NotNull;() // invisible
L0
LINENUMBER 16 L0
ALOAD 0
GETFIELD com/example/kotlinentitytutorial/User.name : Ljava/lang/String;
ARETURN
L1
LOCALVARIABLE this Lcom/example/kotlinentitytutorial/User; L0 L1 0
MAXSTACK = 1
MAXLOCALS = 1
// 생략...
}
Hibernate의 사용자 가이드 문서 를 보면 Entity와 Entity가 가진 인스턴스 변수는 final이 아니어야 한다고 적혀있습니다. 그래서 가이드를 잘 지키는 착한 개발자(?)가 되기 위해서 아래와 같이 allOpen 설정을 추가해주도록 합니다.
allOpen {
annotation("javax.persistence.Entity")
annotation("javax.persistence.MappedSuperclass")
annotation("javax.persistence.Embeddable")
}
위와 같이 설정해주면 더 이상 final 키워드가 들어가 있지 않은 것을 볼 수 있습니다.
public class com/example/kotlinentitytutorial/User extends com/example/kotlinentitytutorial/PrimaryKeyEntity {
@Ljavax/persistence/Entity;()
@Ljavax/persistence/Table;(name="`user`")
// access flags 0x2
private Ljava/lang/String; name
@Ljavax/persistence/Column;(nullable=false, unique=true)
@Lorg/jetbrains/annotations/NotNull;() // invisible
// access flags 0x1
public getName()Ljava/lang/String;
@Lorg/jetbrains/annotations/NotNull;() // invisible
L0
LINENUMBER 16 L0
ALOAD 0
GETFIELD com/example/kotlinentitytutorial/User.name : Ljava/lang/String;
ARETURN
L1
LOCALVARIABLE this Lcom/example/kotlinentitytutorial/User; L0 L1 0
MAXSTACK = 1
MAXLOCALS = 1
// 생략...
}
PrimaryKeyEntity
예제 Entity 코드를 보면 모든 Entity 들이 PrimaryKeyEntity를 상속받은 것을 볼 수 있습니다. PrimaryKeyEntity는 여러 가지 이유로 인해 추가되었는데, 그 이유는 아래와 같습니다.
공통 PrimaryKey 타입 정의
모든 Entity에는 Primary Key가 필요합니다. JPA에서 Primary Key는 @Id로 정의되는데 보통 Long 타입 또는 UUID타입으로 정의됩니다. 저는 Long 타입보다 UUID타입으로 Primary Key를 정의하는 것을 선호하는 편입니다. Long 타입의 Primary Key는 유일성을 보장하는 데 한계가 있기 때문입니다. Entity끼리도 키값이 중복될 수도 있고 UUID의 개수보다 Long 타입의 개수가 현저하게 적기 때문에 최대 개수에 대해 걱정을 하지 않고 싶다면 UUID는 좋은 선택이 될 것입니다.
UUID타입도 단점이 있습니다. Long 타입의 경우 순서를 가질 수 있기 때문에 정렬 시 성능적인 이점을 가져갈 수 있습니다. 그리고 데이터 크기도 UUID에 비해 작기 때문에 저장용량 및 생성 비용을 적게 가져갈 수 있다는 장점도 있습니다. 하지만 일반적인 웹 애플리케이션을 개발하면서 그리고 클라우드 서비스를 사용하면서 저장용량 및 생성 비용을 최적화하는 것은 크게 중요하지 않을 수 있습니다. (이러한 성능이 아주아주 중요한 시스템이라면 ORM 사용 자체를 다시 고려하는 것이 어떨까 합니다) 그렇다면 나머지 단점이 정렬인데, 이 부분도 ULID 를 사용한다면 해결할 수 있습니다. ULID는 UUID와 호환성을 가지면서 시간순으로 정렬할 수 있는 특징을 가지고 있습니다. 그래서 목록 조회 시 Primary Key를 기준으로 정렬을 수행할 수 있습니다.
Java 또는 Kotlin으로 구현한 ULID라이브러리는 많이 있습니다. 그중에서 저는 ULID Creator 를 선호합니다. UUID로 변환하는 함수를 제공하고 무엇보다 Monotonic 함수 를 제공해주기 때문입니다. ULID는 스펙상 밀리초까지만 시간순을 보장해줍니다. 하지만 코드를 작성하다 보면 반복문을 실행하면서 다수의 Entity를 생성하는 경우가 있습니다. 이런 경우 생성된 일반적인 ULID생성함수로는 나노초가 아닌 밀리초 단위까지만 사용하는 ULID 특성상 생성 순서를 보장해주지 않기 때문에 곤란한 상황이 생기곤 합니다. Monotonic ULID는 이를 보완하기 위해 만약 동일한 밀리초가 있다면 다음에 생성되는 ULID의 밀리초를 1 증가시켜서 생성하도록 해줍니다.
이렇듯 모든 Entity 들이 PrimaryKeyEntity를 상속받아 사용하도록 하면 공통된 Primary Key를 사용하도록 할 수 있습니다.
공통 Primary Key 생성 방식 결정
JPA는 Primary Key를 자동으로 생성해주는 @GeneratedValue를 제공합니다. Entity를 생성하고 영속화 시 자동으로 Primary Key를 생성하도록 도와주는 것입니다. 편리한 기능이지만 저는 @GeneratedValue 사용을 좋아하지 않습니다. 그 이유는 다음과 같습니다.
Nullable 타입을 유도한다
Spring Data JPA 의 save함수를 보면 아래와 같은 코드가 있습니다.
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
entityInformation.isNew가 true이면 즉, Entity가 새롭게 생성되었다면 EntityManager.persist 함수를, 이미 존재하는 Entity라면 EntityManager.merge함수를 실행합니다. 그럼 새롭게 생성되었다는것을 어떻게 판단할까요? Entity의 신규 생성 여부는 JpaMetamodelEntityInformation를 거쳐 AbstractEntityInformation.isNew를 통해 판단됩니다.
public boolean isNew(T entity) {
ID id = getId(entity);
Class<ID> idType = getIdType();
if (!idType.isPrimitive()) {
return id == null;
}
if (id instanceof Number) {
return ((Number) id).longValue() == 0L;
}
throw new IllegalArgumentException(String.format("Unsupported primitive id type %s", idType));
}
위 코드를 보면 Entity의 ID가 원시 타입이 아니면 null 여부를 통해 새롭게 생성된 Entity인지 여부를 결정하는 것을 볼 수 있습니다. 즉, Primary Key가 nullable한 타입이라는 것입니다. 조금만 생각해보면 이상합니다. 데이터베이스는 Primary Key를 Not Null 값으로 강제합니다. 그리고 Entity 입장에서도 식별자가 Nullable하다는 것은 지극히 어색합니다.
생성한 값과 영속화된 값이 다르다
그렇다면 Long 타입은 어떨까요? 다시 위 코드를 보면 숫자 형인 경우 0인 값이면 새롭게 생성된 Entity인지 판단합니다. 그래서 참조 타입이 아닌 원시 타입인 경우 그나마 나은 게 적어도 Nullable하지는 않기 때문입니다. 하지만 이 또한 상당히 어색합니다. 왜냐하면 애플리케이션 내에서 생성된 Entity는 영속화하기 전까지는 모두 0인 ID를 가지기 때문입니다. 그렇다면 이 Entity 들은 모두 같은 Entity일까요? 아닙니다. 다르다고 봐야 합니다. 그럼 동일성을 ID가 0인 경우는 제외해야 할까요? 그것은 참으로 근시안적인 해결책이라 생각됩니다.
채번을 유발한다
@GeneratedValue를 사용하는 방법은 다양합니다. (자세한 생성 방법은 여기 를 참고해 주세요) auto_increment나 시퀀스, 시퀀스 테이블을 활용하는 방법들은 모두 데이터베이스에 그 책임을 전가하고 부하를 유발합니다. 작은 규모의 애플리케이션에서는 괜찮을진 몰라도 대량의 트래픽을 다루기 위해 많은 서버를 두고 있는 애플리케이션에서는 이러한 채번 활동이 데이터베이스에 상당한 부담을 주게 됩니다.
그렇다면 @GeneratedValue를 사용하지 않고 Entity의 Primary Key를 다루는 방법은 무엇일까요? 간단합니다. Entity 생성 시 Primary Key도 함께 생성해주면 됩니다. 앞서 Long 타입보다 ULID타입으로 Primary Key 타입을 두는 것을 선호한다고 말했었습니다. 그 이유가 여기에도 있는데요. Long 타입은 랜덤한 값을 주기가 조금 모호합니다. 날짜 객체를 Long 타입으로 바꿔서 사용할 수는 있을 것 같기는 합니다. 하지만 1부터 시작하고 싶다면 이 방법도 좋은 대안이라 하긴 힘듭니다. ULID는 어디서 생성하든 중복된 값이 생성될 확률이 거의 없다고 봐도 무방합니다. 그래서 PrimaryKeyEntity를 통해 Entity를 생성할 때 무조건 ULID가 자동으로 생성하도록 강제하여 위에서 말하는 단점들을 회피할 수 있습니다.
Persistable 구현
Primary Key를 영속화 전에 미리 생성해주는 방식으로 하면 주의할 점이 있습니다. 앞서 Primary Key가 참조변수 타입이면 null인 경우에만 신규 생성 Entity로 간주한다고 했었습니다. 그래서 ULID를 Entity를 생성할 때 함께 생성해서 영속화를 하면 EntityManager.persist 함수가 아닌 EntityManager.merge 함수가 호출됩니다. 그래서 아래와 같이 저장하기 전에 Primary Key를 가진 데이터가 존재하는지 여부를 확인하는 쿼리가 한번 실행됨을 볼 수 있습니다.
@Entity
class Foo(
name: String
) {
@Id
val id: UUID = UUID.randomUUID()
@Column
var name: String = name
protected set
}
@Test
fun test() {
val foo = Foo("test")
fooRepository.save(foo)
fooRepository.flush()
}
Hibernate:
select
foo0_.id as id1_3_0_,
foo0_.name as name2_3_0_
from
foo foo0_
where
foo0_.id=?
Hibernate:
insert
into
foo
(name, id)
values
(?, ?)
결과적으로는 새롭게 Entity가 생겨서 문제가 없지만 한번 조회한 후 저장하는 방법은 불필요한 쿼리를 실행시키기 때문에 좋아 보이진 않습니다. 다행히 Spring Data에서 이러한 문제를 해결하기 위한 방법으로 Persistable 인터페이스를 제공해줍니다. Persistable인터페이스는 getId와 isNew 함수를 제공하는데 isNew함수는 위에서 언급한 entityInformation.isNew(entity)에서 활용됩니다. Persistable인터페이스를 구현한 Entity를 영속화하면 JpaPersistableEntityInformation.isNew함수가 호출되며 여기서 Persistable.isNew함수를 호출합니다.
@Override
public boolean isNew(T entity) {
return entity.isNew();
}
그럼 이제 위에서 예시로 들었던 Entity에 Persistable을 구현하도록 해보겠습니다. 테스트 코드를 실행하면 insert쿼리만 실행됨을 확인할 수 있습니다.
@Entity
class Foo(
name: String
) : Persistable<UUID> {
@Id
private val id: UUID = UUID.randomUUID()
@Column
var name: String = name
protected set
override fun getId(): UUID = id
override fun isNew(): Boolean = true
}
Hibernate:
insert
into
foo
(name, id)
values
(?, ?)
다만, 이렇게 설정하는 경우 이슈가 있습니다. 바로 delete를 호출할 때 삭제 쿼리가 실행되지 않는 이슈입니다. SimpleJpaRepository.delete함수를 살펴보겠습니다.
@Override
@Transactional
@SuppressWarnings("unchecked")
public void delete(T entity) {
Assert.notNull(entity, "Entity must not be null!");
if (entityInformation.isNew(entity)) {
return;
}
Class<?> type = ProxyUtils.getUserClass(entity);
T existing = (T) em.find(type, entityInformation.getId(entity));
// if the entity to be deleted doesn't exist, delete is a NOOP
if (existing == null) {
return;
}
em.remove(em.contains(entity) ? entity : em.merge(entity));
}
아주 익숙한 코드가 눈에 띕니다. entityInformation.isNew를 호출해서 참이면 즉, 새롭게 생성된 Entity이면 EntityManager.remove 함수를 호출하지 않는 것입니다. 실제로도 그런지 테스트해보겠습니다.
@Test
fun test() {
val foo = Foo("test")
fooRepository.save(foo)
fooRepository.flush()
fooRepository.delete(foo)
fooRepository.flush()
}
Hibernate:
insert
into
foo
(name, id)
values
(?, ?)
insert 쿼리 외에 아무 쿼리도 보이지 않습니다. entityInformation.isNew가 true로 반환되기 때문에 그런 것입니다. 그렇다면 어떻게 해결할 수 있을까요? 곰곰이 생각해보면 isNew가 true인 경우는 이제 막 Entity를 생성해서 영속화를 하기 전까지입니다. 그렇다면 영속화를 한 이후와 Entity를 조회하였을 때는 isNew가 false가 되어야 합니다.
이 부분을 해결하기 위해 JPA의 @PostPersist와 @PostLoad를 활용하기로 했습니다. @PostPersist와 @PostLoad는 JPA의 수명주기 이벤트에 대한 콜백 방법을 정의하는 것으로 각각 영속화 이후와 영속화한 데이터를 조회한 이후에 함수가 실행되도록 할 수 있습니다. 위 예시 코드에 추가해보겠습니다. isNew의 상태를 관리해야 하므로 isNew Property를 추가하고 영속화는 하지 않도록 @Transient를 선언해주었습니다.
@Entity
class Foo(
name: String
) : Persistable<UUID> {
@Id
private val id: UUID = UUID.randomUUID()
@Column
var name: String = name
protected set
override fun getId(): UUID = id
@Transient
private var _isNew = true
override fun isNew(): Boolean = _isNew
@PostPersist
@PostLoad
protected fun load() {
_isNew = false
}
}
Hibernate:
insert
into
foo
(name, id)
values
(?, ?)
Hibernate:
delete
from
foo
where
id=?
로그를 보면 delete 쿼리가 정상적으로 실행됨을 볼 수 있습니다.
위와 같은 이슈들이 있을 수 있기 때문에 Persistable을 구현할 때 이 부분들을 꼭 염두에 두고 정의하면 좋겠습니다.
공통 동일성 보장
앞서 Entity는 같은 식별자를 가진다면 동일한 객체라고 판단해야 하므로 equals와 hashCode를 재정의해주어야 한다고 이야기했었습니다. 모든 Entity마다 equals와 hashCode를 재정의해주는 것은 불편한 일입니다. 변경 사항이 발생했을 때 반복적으로 코드를 수정하는 행위도 좋은 코드라 하기 힘들 것입니다. 그래서 PrimaryKeyEntity에 equals와 hashCode를 재정의해두고 이를 공통으로 활용할 수 있도록 하면 좋습니다. 물론 이렇게 할 수 있는 이유는 모든 Entity는 식별자를 기준으로 동일함을 판단하기 때문입니다.
@MappedSuperclass
abstract class PrimaryKeyEntity : Persistable<UUID> {
@Id
@Column(columnDefinition = "uuid")
private val id: UUID = UlidCreator.getMonotonicUlid().toUuid()
// 생략...
override fun equals(other: Any?): Boolean {
if (other == null) {
return false
}
if (this::class != other::class) {
return false
}
return id == (obj as PrimaryKeyEntity).id
}
override fun hashCode() = Objects.hashCode(id)
}
이렇게 하면 PrimaryKeyEntity를 이용하여 모든 동일성을 보장할 수 있으니 손쉽게 끝!! 이라고 외칠 수 있겠으나 아쉽게도 이번에도 이슈가 있습니다.
이번에도 역시나 JPA의 메커니즘에 의해 발생하는 이슈인데, 상황을 한번 보겠습니다. 위에서 정의한 User Entity와 Board Entity를 영속화한 후 Board Entity를 재조회하여 User Entity가 기존에 추가한 User Entity와 일치하는지 보겠습니다.
@Test
fun test() {
val user = User("홍길동")
val boardInformation = BoardInformation(null, 1)
val board = Board("게시판1", "내용1", boardInformation, user, setOf())
testEntityManager.persist(user)
testEntityManager.persist(board)
testEntityManager.flush()
testEntityManager.clear()
val actual = boardRepository.findById(board.id).get()
assertTrue(user == actual.writer)
}
expected: <true> but was: <false>
Expected :true
Actual :false
성공할 것을 예상했지만, 결과는 실패합니다. 이유가 무엇일까요? 범인은 바로 Hibernate Proxy 때문입니다. JPA의 구현체인 Hibernate는 성능 최적화를 위해 연관관계 조회 시 꼭 필요할 때까지 조회 쿼리 호출을 지연시키는 지연 조회(Lazy Loading)를 지원합니다. 그래서 연관관계를 조회하는 쿼리가 실행되어 실제 Entity가 생성되기 전까지 Proxy 객체를 미리 생성해서 넣어두었다가 실제 조회가 되면 Entity를 Proxy와 교체하는 방식으로 동작합니다.
다시 테스트 코드에서 user == actual.writer가 true가 아니라 false로 반환되는지 equals를 다시 한번 살펴보겠습니다.
override fun equals(other: Any?): Boolean {
if (other == null) {
return false
}
if (this::class != other::class) {
return false
}
return id == (obj as PrimaryKeyEntity).id
}
첫 번째 조건문에서는 null이 아니므로 넘어가고, 두 번째 조건문이 아마 범인이지 않을까 생각됩니다. this::class와 other::class를 출력해보겠습니다.
override fun equals(other: Any?): Boolean {
if (other == null) {
return false
}
println(this::class) // class com.example.kotlinentitytutorial.User
println(other::class) // class com.example.kotlinentitytutorial.User$HibernateProxy$bl4KAli0
println(this::class != other::class) // true
if (this::class != other::class) {
return false
}
return id == (obj as PrimaryKeyEntity).id
}
this::class는 User Entity임이 확인되지만 other::class는 User$HibernateProxy$bl4KAli0 인 것을 확인할 수 있습니다. 그래서 서로 다른 객체라 판단하는 것입니다. 즉, board.writer는 지연 로딩으로 인해 아직 쿼리가 실행되지 않았으므로 HibernateProxy객체로 존재하게 되는 것입니다.
그럼 이 문제를 어떻게 해결하면 좋을까요? 첫 번째 떠오르는 방법은 즉시 조회(Eager Loading)를 사용하는 방법입니다. Board가 조회될 때 User도 바로 조회 하도록 하면 HibernateProxy로 Entity를 대체하지 않을 테니 말입니다. 실제로 아래와 같이 fetchType을 변경하여 위 테스트를 실행하면 성공함을 볼 수 있습니다.
class Board {
// 생략...
@ManyToOne(fetch = FetchType.EAGER, optional = false)
var writer: User = writer
protected set
}
하지만 Entity 조회 시 반드시 연결된 연관관계를 사용해야 하는 상황이라면 이러한 해결책이 맞을 순 있으나 사용하지 않을 때도 쿼리를 무조건 실행하도록 모든 연관관계를 정의하면 성능적으로 아주 좋지 않을 것입니다. 데이터베이스에 부하를 주는 것은 물론이거니와 의도치 않은 N+1 문제를 야기할 수도 있습니다.
그래서 해결할 수 있는 다른 방법은 바로 equals를 아래와 같이 다시 정의하는 것입니다.
override fun equals(other: Any?): Boolean {
if (other == null) {
return false
}
if (other !is HibernateProxy && this::class != other::class) {
return false
}
return id == getIdentifier(other)
}
private fun getIdentifier(obj: Any): Serializable {
return if (obj is HibernateProxy) {
obj.hibernateLazyInitializer.identifier
} else {
(obj as PrimaryKeyEntity).id
}
}
코드를 하나하나 살펴보면 클래스 타입을 체크하는 부분에서 HibernateProxy는 제외하도록 변경하였습니다. 그런 다음 식별자를 가져올 때 HibernateProxy 객체이면 obj.hibernateLazyInitializer.identifier를 통해 식별자를 가져오도록 하고 HibernateProxy 객체가 아니면 PrimaryKeyEntity.id를 가져오도록 하였습니다. equals 코드를 변경한 후 위 테스트를 다시 실행해보면 지연 조회인 경우에도 정상적으로 동일함을 판단해줌을 확인할 수 있습니다.
지금까지 PrimaryKeyEntity를 활용하는 방법에 대해 알아보았습니다. 설명이 길어 다소 복잡할 수 있다는 생각이 듭니다. 그래서 간단하게 정리하자면 식별자의 타입과 생성 방법 그리고 동일성을 보장해주는 코드를 Entity 전체에 통일시키기 위한 용도로 PrimaryKeyEntity를 사용한다고 보면 됩니다. (여기서 네이밍은 크게 중요하지 않으니 원하는 이름으로 사용해주세요!)
Property 접근제어
다음으로 가장 많이 고민한 부분이 바로 Entity의 Property에 대한 접근제어입니다. 앞서 문제상황에서 이야기한 바와 같이 Java 코드에서 사용하던 패턴과 Entity를 단순한 데이터베이스의 테이블 정보를 담은 데이터 구조체로만 생각함으로써 오는 좋지 못한 사용은 우리의 애플리케이션을 더욱 복잡하고 유지보수하기 어렵게 만듭니다. 그래서 Entity의 Property의 변경을 최소화하고 꼭 필요한 경우에 변경할 수 있도록 캡슐화를 해줄 필요가 있습니다. 아무리 Entity의 Property가 생명주기 동안에 변경 가능하다고 해도 말입니다. (나의 이름을 누군가가 마음대로 바꿀 수 있다면 좋을까요?)
식별자의 생성과 조회는 PrimaryKeyEntity에게 위임했으니 식별자 관리에 대해서는 생략하겠습니다. 간단하게 짚고 넘어가자면 식별자는 Entity의 생명주기 동안 절대 바뀌지 않아야 하므로 불변변수로 선언합니다.
@Id
@Column(columnDefinition = "uuid")
private val id: UUID = UlidCreator.getMonotonicUlid().toUuid()
그렇다면 다른 Property 들은 어떻게 선언하면 좋을까요? Entity의 Property 들은 생명주기 동안 변경 가능하다고 이야기했었습니다. 그래서 불변(immutable) Property가 아닌 변하는(muatable) Property로 선언하는 것이 이상적입니다.
@Entity
class User(
@Column(nullable = false, unique = true)
var name: String,
) : PrimaryKeyEntity()
하지만 저는 저의 이름을 누군가가 마음대로 변경하는 것은 원치 않습니다. 비록 Kotlin은 Property라 setter를 재정의해줄 수 있지만 앞서 말했다시피 목적을 나타내지 않는 setter는 좋아할 수라 보기 어렵습니다. 그래서 외부에서 name을 변경하는 것을 막으면 좋겠습니다. 그러나 위 코드처럼 정의하면 setter를 외부에서 사용하지 못하도록 막을 방법이 없습니다. 그래서 아래와 같은 방법으로 정의할 수 있습니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
}
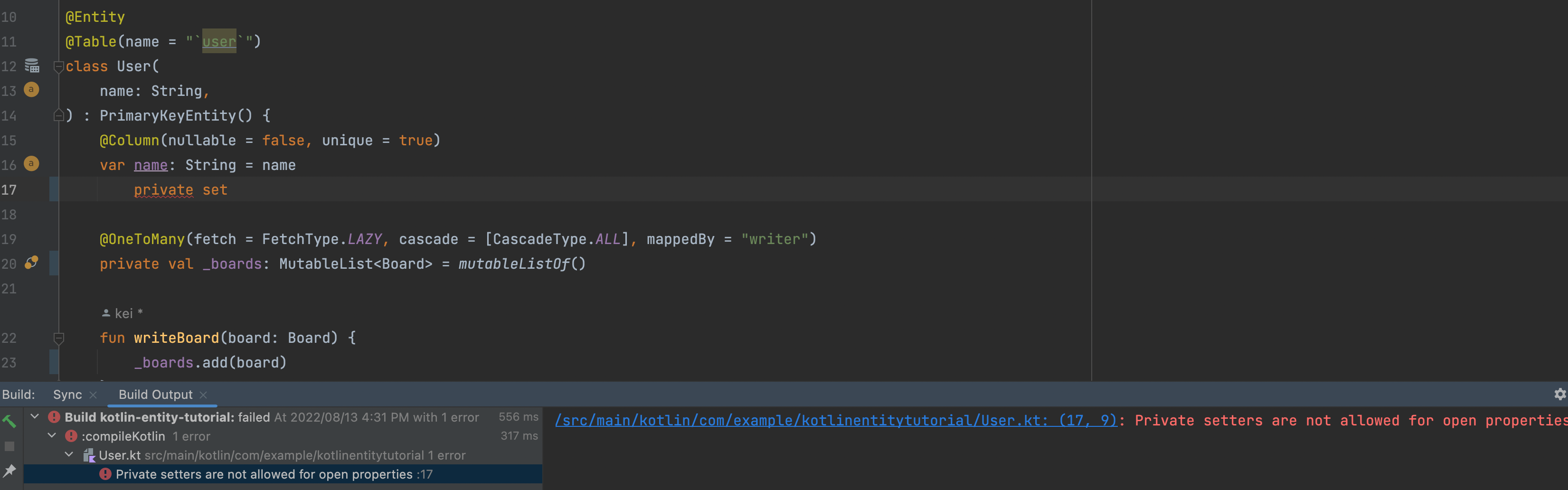
위와 같이 protected set을 사용하면 User Entity 자신 또는 상속받은 Entity에서만 name을 변경할 권한이 생깁니다. 여기서 왜 setter에 대한 접근 권한을 private가 아니라 protected로 정의했는지 궁금할 것입니다. 앞서 우리는 Entity 클래스에 대해 allOpen 설정을 해두었을 것입니다. open property의 경우 private setter는 허용되지 않기 때문에 아래와 같이 컴파일 에러가 발생합니다.
한편 Entity의 Property 중에 변경이 전혀 필요하지 않은 Property가 있을 수 있습니다. 가령 생성일시와 같은 Property는 한번 생성되고 나면 변경되지 않는 것이 이상적입니다. 그래서 아래와 같이 선언할 수 있습니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@Column(nullable = false)
val createdAt: LocalDateTime = LocalDateTime.now()
}
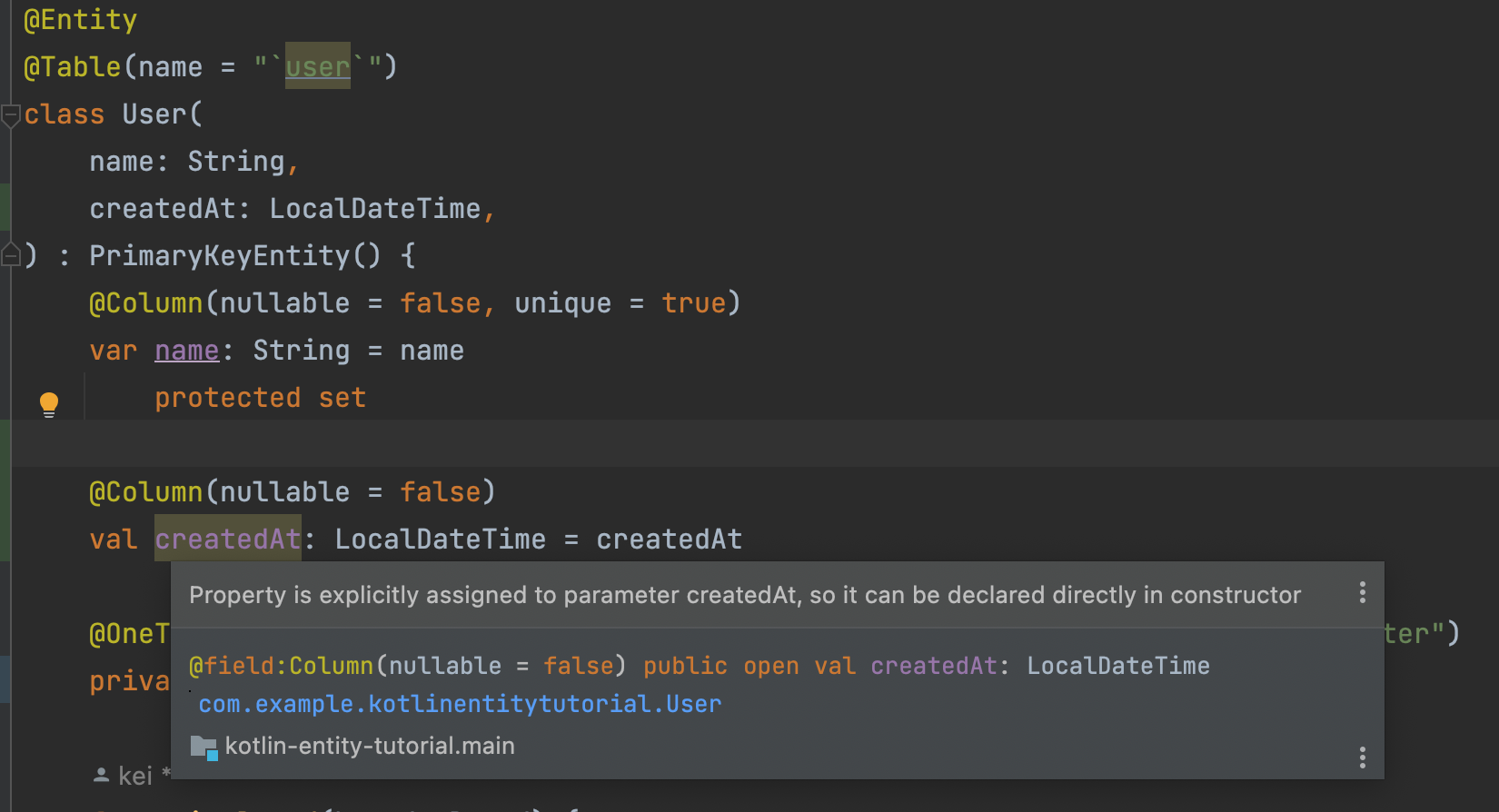
다만 이 Property를 생성자 매개변수를 통해 초기화한다면 조금 불편함이 생깁니다. 생성자 매개변수에서 직접 선언할 수 있으니 생성자 매개변수로 위치를 이동하라고 IDEA에서 warning을 표시하는 것입니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
createdAt: LocalDateTime,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@Column(nullable = false)
val createdAt: LocalDateTime = createdAt
}
이를 해결할 방법은 여러 가지가 있습니다. 모두 일장일단이 있으니 선호하는 방식을 채택하면 좋겠습니다.
생성자 매개변수로 이동
IDEA가 가이드하는 대로 생성자 매개변수로 위치를 옮기는 것입니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
@Column(nullable = false)
val createdAt: LocalDateTime,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
}
하지만 이렇게 되면 JPA의 Column이 선언된 Property 들이 생성자에도 존재하게 되고 클래스 내부에도 존재하게 됩니다. 개인적으로 일관성도 떨어져 보이고 가독성이 썩 좋진 않아 보입니다. 하지만 별도의 @Suppress도 달아주지 않고 불변 Property를 사용할 수 있다는 장점이 있습니다.
Suppress 추가
다음은 @Suppress를 추가하는 방법입니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
createdAt: LocalDateTime,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@Suppress("CanBePrimaryConstructorProperty")
@Column(nullable = false)
val createdAt: LocalDateTime = createdAt
}
이렇게 @Suppress를 추가해주면 더 이상 IDEA에서 warning을 표시하지 않습니다. Property 위에 선언하는 게 불편하다면 class나 file 레벨로 끌어 올릴 수도 있습니다. warning이 크리티컬한 위험성을 포함하는 것이 아니라면 이렇게 IDEA에 표시되지 않도록 처리하는 것도 합리적인 방법이 될 수 있습니다. 하지만 예기치 못한 상황이 생길 수 있으니 되도록 보수적으로 사용하는 것을 권장합니다. 자칫 무분별하게 @Suppress를 사용하는 버릇을 들이면 중요한 위험 알림도 무시할 수 있으니 말입니다.
protected set 설정
도매인 적으로는 생성일시는 생명 주기상 변하지 않아야 합니다. 하지만 Entity 입장에서는 모든 Property가 변경 가능하다고 봅니다. 그래서 Entity 내부에서만 변경할 수 있도록 선언해두고 외부에서는 변경이 가능하지 않도록 변경할 수를 제공하지 않는다면 특별히 문제가 되지 않을 것입니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
createdAt: LocalDateTime,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@Column(nullable = false)
var createdAt: LocalDateTime = createdAt
protected set
}
이렇게 하면 @Suppress를 추가하지 않고도 생성자 매개변수로 이용할 수 있습니다. 하지만 Entity 내부에서 변경 가능성을 열어두었기 때문에 위험성을 내포하고 있다는 단점이 있기는 합니다. (사실 불변(immutable) Property로 선언해도 개발자가 변경(mutable) Property로 바꾸는 것을 막지 못한다는 건 똑같다고 생각합니다)
지금까지 Property에 대한 접근제어에 대한 팁을 적어보았습니다. Entity의 캡슐화는 애플리케이션 개발할 시 상당히 중요한 포인트입니다. 상태의 변경은 부작용(Side-effect)을 유발합니다. 부작용을 최소화해서 우리가 만드는 제품의 복잡성을 최대한 줄이기 위해 항상 고민하면 좋겠습니다.
nullable
어찌 보면 간단한 팁이지만 놓치기 쉬운 부분입니다. 새롭게 애플리케이션을 만들 때보다 기존에 Java로 작성되어있는 코드를 Kotlin으로 전환할 때 더 높은 확률로 발생하는 이슈입니다. 바로 데이터베이스의 스키마와 Entity의 스키마가 불일치하는 경우인데, 타입이 다른 것은 대부분 JPA가 애플리케이션 빌드 시 잡아서 잘못 정의되었음을 알려줍니다. 하지만 nullable한 Column을 Entity에 non-nullable하게 선언한 경우 만약 Column에 값이 null이라면 런타임 시 오류가 발생합니다.
Java로 Entity를 작성할 때는 모두 nullable한 Property이기 때문에 이를 염두에 두고 코드를 작성하거나 방어코드를 넣어두어서 오류를 쉽게 감지할 수 있도록 조치를 할 수 있습니다. (사실 실무를 하면서 이렇게 꼼꼼하게 방어코드를 작성하는 경우를 많이 보진 못했습니다 ^^;;) 하지만 Kotlin은 타입으로 non-nullable을 보장해 줄 수 있습니다. 그래서 데이터베이스의 Column은 nullable인데 Entity의 Property가 non-nullable로 선언되어 런타임 시 예기치 못한 오류가 발생하는 경우를 종종 보았습니다.
개인적으로는 이를 방지하기 위해서 @Column에 nullable 여부를 함께 적어주는 것을 선호합니다. Flyway 등을 이용해서 DDL을 적어주었더라도 Entity를 정의할 때 생략할 수 있는 부분이 있더라도 최소한의 DDL 정보를 적어주면 좋다고 생각하는데 그중 하나가 바로 nullable속성입니다. @Column의 nullable속성은 기본이 true이므로 nullable한 Property라면 생략해주어도 된다 생각합니다. 하지만 non-nullable한 Property라면 @Column(nullable = false)과 같이 선언해주는 습관을 지니면 위 사례와 같이 예기치 않은 오류를 만날 가능성을 많이 줄일 수 있습니다. @JoinColumn에도 마찬가지고 연관관계에서도 마찬가지입니다.
@Column(nullable = false)
var title: String = title
protected set
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(nullable = false)
var writer: User = writer
protected set
연관관계
Java로 JPA Entity를 정의해보았던 개발자라면 Kotlin으로 Entity를 정의할 때 연관관계를 어떻게 정의하면 좋을지 고민을 많이 해보았겠다고 생각합니다. 아마 Java에서는 편하게 정의했던 것들을 Kotlin으로 정의할 때는 상당히 번거롭다고 느껴지기도 할 것입니다. 저는 오히려 잘못 사용되고 있던 패턴을 올바르게 사용하도록 바꾸어주었다고 생각합니다. 그럼 제가 생각하는 JPA에서 Entity의 연관관계를 좀 더 잘 사용하기 위한 팁들을 알아보겠습니다.
연관관계는 Entity 자체로 주입하자
앞서 안티 패턴을 소개하던 부분에서 lateinit을 사용하는 사례를 소개했었습니다. 이러한 패턴이 발생하는 이유는 Entity 간에 연관관계를 맺어줄 때 객체적으로 접근한 것이 아니라 데이터베이스적으로 접근하기 때문이라 생각됩니다. 이게 무슨 말이냐고 하면 만약 Board Entity가 생성될 때 User Entity가 필요하다고 가정해보겠습니다. 객체적으로 생각하면 Board는 User 정보를 가지고 있어야 하므로 생성자 매개변수로 User를 받을 것입니다.
@Entity
class Board(
// 생략...
writer: User,
) : PrimaryKeyEntity() {
// 생략...
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(nullable = false)
var writer: User = writer
protected set
}
하지만 데이터베이스적으로 접근하면 Board Entity는 user_id를 가지고 있으므로 user_id를 매개변수로 받고 연관관계 조회는 JPA가 알아서 해줄 것이니 따로 선언하려고 하지 않을 것입니다.
@Entity
class Board(
// 생략...
writerId: UUID,
) : PrimaryKeyEntity() {
// 생략...
@Column(nullable = false)
var writerId: UUID = writerId
protected set
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "writerId", nullable = false)
lateinit var writer: User
}
이러한 패턴이 나오는 또 다른 이유는 아마 다음과 같이 애플리케이션을 개발하기 때문일 것입니다.
data class BoardCreationCommand(
// 생략...
val writerId: UUID,
)
@RestController
class Controller(
private val boardService: BoardService,
) {
@PostMapping("/boards")
fun createBoard(@RequestBody command: BoardCreationCommand): BoardDto =
BoardDto(boardService.create(command))
// 생략...
}
@Service
@Transactional(readOnly = true)
class BoardService(
private val boardRepository: BoardRepository,
) {
@Transactional
fun create(command: BoardCreationCommand): Board {
val entity = Board(command.writerId)
return boardRepository.save(entity)
}
// 생략...
}
클라이언트에서는 Board를 생성하기 위해 User Entity의 정보를 모두 보내는 것보다 User의 식별자만 전달하는 것이 효율적입니다. 그래서 User의 식별자만 전달하게 되는데 서버에서는 그 정보를 그대로 이용해서 Entity를 생성하는 데 사용하기 때문입니다. 저는 이렇게 사용하는 패턴이 많은 문제를 가지고 있다고 생각합니다.
첫 번째로 테스트하기에 용이하지 않습니다. Entity를 생성하고 연관관계를 조회할 때 JPA에 의존하게 되면 단위테스트는 애초에 불가능해집니다. 결국 통합테스트나 기능테스트로밖에 Entity가 가진 기능들을 테스트할 수밖에 없습니다. 왜냐하면 Entity가 온전하지 않고 외부 리소스(JPA)에 의존하는 코드이기 때문입니다.
두 번째, 데이터베이스와 일치하지 않는 타입을 유발합니다. Entity를 생성자 매개변수로 전달하지 않고 lateinit을 사용하지 않으려면 nullable한 타입으로 선언해서 JPA가 연관관계를 불러와 주지 않는다면 null을 반환하도록 풀어야 합니다. 하지만 도메인적으로 게시글이 생성되었는데 작성자가 존재하지 않는 게 과연 옳은 구현일까요?
세 번째, 위 문제점들을 해결하기 위해 불필요한 코드들이 양산됩니다. 조금 귀찮다고 올바르게 사용하지 않다 보면 이를 우회하기 위해 더 많은 불필요한 코드들이 양산됩니다.
그러므로 애플리케이션을 개발할 때 위 코드를 아래처럼 바꿔서 사용하면 좋겠습니다.
data class BoardCreationCommand(
// 생략...
val writerId: UUID,
)
@RestController
class Controller(
private val boardService: BoardService,
) {
@PostMapping("/boards")
fun createBoard(@RequestBody command: BoardCreationCommand): BoardDto =
BoardDto(boardService.create(command))
// 생략...
}
@Service
@Transactional(readOnly = true)
class BoardService(
private val userRepository: UserRepository,
private val boardRepository: BoardRepository,
) {
@Transactional
fun create(command: BoardCreationCommand): Board {
val user = getUserById(command.writerId)
val entity = Board(user)
return boardRepository.save(entity)
}
// 생략...
}
양방향 관계인 경우에 양쪽다 Entity를 주입해주자
Hibernate 가이드 문서 를 보면 양방향 관계 시 Entity 간의 관계가 형성될 때마다 두 Entity 모두 동기화를 시켜줘야 한다고 말하고 있습니다.
Whenever a bidirectional association is formed, the application developer must make sure both sides are in-sync at all times.
앞서 말한 객체적으로 접근하면 어찌 보면 당연한 이야기입니다. Board Entity가 생성될 때 User Entity가 매개변수로 사용된다고 한다면 User Entity 입장에서도 Board가 추가되는 것이니 아래와 같이 User.writeBoard함수가 호출되어야 합니다.
@Entity
class Board(
writer: User,
) : PrimaryKeyEntity() {
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(nullable = false)
var writer: User = writer
protected set
// 생략...
init {
writer.writeBoard(this)
}
}
@Entity
@Table(name = "`user`")
class User(
name: String,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@OneToMany(fetch = FetchType.LAZY, cascade = [CascadeType.ALL], mappedBy = "writer")
protected val mutableBoards: MutableList<Board> = mutableListOf()
fun writeBoard(board: Board) {
mutableBoards.add(board)
}
}
외부에 노출하는 연관관계 Collection은 Immutable Collection을 노출하자
Kotlin은 두 가지 유형의 Collection 인터페이스를 제공해줍니다. Immutable Collection과 Mutable Collection인데 다이어그램을 보면 아래와 같습니다. (출처: Kotlin 공식문서)

Immutable Collection은 말 그대로 요소를 변경할 수 없도록 설계된 Collection이고 Mutable Collection은 Immutable Collection에 setter를 추가한 Collection이라 보면 됩니다.
JPA에서 연관관계의 요소의 변경은 데이터베이스의 변경을 유발합니다. 그래서 아래와 같이 Property를 불변으로 선언하더라도 언제든지 외부에서 연관관계를 변경할 수 있습니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@OneToMany(fetch = FetchType.LAZY, cascade = [CascadeType.ALL], mappedBy = "writer")
val mutableBoards: MutableList<Board> = mutableListOf()
}
@DataJpaTest(showSql = true)
class UserRepositoryTest {
@Autowired private lateinit var userRepository: UserRepository
@Autowired private lateinit var testEntityManager: TestEntityManager
@Test
fun test() {
val user = User("홍길동")
val board1 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
val board2 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
testEntityManager.persist(user)
testEntityManager.persist(board1)
testEntityManager.persist(board2)
testEntityManager.flush()
testEntityManager.clear()
val findUser = userRepository.findById(user.id).get()
val board3 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
findUser.mutableBoards.add(board3)
testEntityManager.merge(findUser)
testEntityManager.flush()
testEntityManager.clear()
}
}
Hibernate:
insert
into
"user"
(name, id)
values
(?, ?)
Hibernate:
insert
into
board
(content, created_at, link, rank, title, "writer_id", id)
values
(?, ?, ?, ?, ?, ?, ?)
Hibernate:
insert
into
board
(content, created_at, link, rank, title, "writer_id", id)
values
(?, ?, ?, ?, ?, ?, ?)
Hibernate:
select
user0_.id as id1_4_0_,
user0_.name as name2_4_0_
from
"user" user0_
where
user0_.id=?
Hibernate:
select
board0_.id as id1_0_1_,
board0_.content as content2_0_1_,
board0_.created_at as created_3_0_1_,
board0_.link as link4_0_1_,
board0_.rank as rank5_0_1_,
board0_.title as title6_0_1_,
board0_."writer_id" as writer_i7_0_1_,
mutabletag1_.board_id as board_id1_2_3_,
tag2_.id as tag_id2_2_3_,
tag2_.id as id1_3_0_,
tag2_."key" as key2_3_0_,
tag2_."value" as value3_3_0_
from
board board0_
left outer join
board_tag_assoc mutabletag1_
on board0_.id=mutabletag1_.board_id
left outer join
tag tag2_
on mutabletag1_.tag_id=tag2_.id
where
board0_.id=?
Hibernate:
insert
into
board
(content, created_at, link, rank, title, "writer_id", id)
values
(?, ?, ?, ?, ?, ?, ?)
로그를 보면 알 수 있다시피 add 함수를 통해 User가 가진 Board를 외부에서 자유롭게 추가할 수 있음을 볼 수 있습니다. 이러한 방식은 앞서 말한 Entity의 캡슐화를 위반하는 것이므로 부작용을 유발할 가능성이 높습니다. 그러면 위와 같은 현상이 발생하지 않도록 하기 위해서는 어떻게 코드를 작성하면 좋을까요? 연관관계를 변경하는 일은 Entity의 특성상 필요한 일이므로 MutableList로 선언하는 것이 좋다고 생각됩니다. 그럼 MutableList는 내부에서만 접근할 수 있도록 하고 ImmutableList를 외부에 노출하도록 하면 됩니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@OneToMany(fetch = FetchType.LAZY, cascade = [CascadeType.ALL], mappedBy = "writer")
protected val mutableBoards: MutableList<Board> = mutableListOf()
val boards: List<Board> get() = mutableBoards
}
@Test
fun test() {
val user = User("홍길동")
val board1 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
val board2 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
testEntityManager.persist(user)
testEntityManager.persist(board1)
testEntityManager.persist(board2)
testEntityManager.flush()
testEntityManager.clear()
val findUser = userRepository.findById(user.id).get()
val board3 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
findUser.boards.add(board3) // compile error : Unresolved reference: add
}
다만 위와같은 방식에도 문제점은 존재합니다. 아래 코드를 보겠습니다.
@Test
fun test() {
val user = User("홍길동")
val board1 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
val board2 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
testEntityManager.persist(user)
testEntityManager.persist(board1)
testEntityManager.persist(board2)
testEntityManager.flush()
testEntityManager.clear()
val findUser = userRepository.findById(user.id).get()
val boards = findUser.boards
assertEquals(2, boards.size)
val board3 = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
findUser.writeBoard(board3)
assertEquals(2, boards.size) // assert error : expected: <2> but was: <3>
}
우리는 User.boards를 조회했을 때 보통 조회한 시점에 게시판 목록이 그대로 boards 변수에 담겨 있을 것이라 기대합니다. 하지만 User.writeBoard함수가 호출되고 난 후 boards변수에 담겨있는 게시판 목록의 수가 바뀐 것을 볼 수 있습니다. 지금은 간단한 코드이기 때문에 그 이유를 쉽게 찾을 수 있지만 여러 함수가 복잡하게 얽히고설켜 있으면 그 코드를 추적하는 것은 참 어려운 일입니다. 이러한 이유로 불변(Immutable)은 복잡함을 줄이고 코드를 단순화할 수 있다고 하는 것입니다. 자 그럼 이 문제를 해결할 수 있는 코드를 보겠습니다.
@Entity
@Table(name = "`user`")
class User(
name: String,
) : PrimaryKeyEntity() {
@Column(nullable = false, unique = true)
var name: String = name
protected set
@OneToMany(fetch = FetchType.LAZY, cascade = [CascadeType.ALL], mappedBy = "writer")
protected val mutableBoards: MutableList<Board> = mutableListOf()
val boards: List<Board> get() = mutableBoards.toList()
fun writeBoard(board: Board) {
mutableBoards.add(board)
}
}
위와 같이 mutableBoards에 toList함수를 사용해서 Collection의 요소를 복제하여 반환하면 더 이상 mutableBoards가 변경되어도 테스트 코드에 선언된 baords에 영향을 미치지 않게 됩니다. Entity의 Collection을 다룰 때 이 부분을 잊지 않도록 꼭 염두에 두길 바랍니다.
단순하게 N:M 관계를 맺어주고 싶다면 ManyToMany를 선언하자
JPA를 사용하는 많은 개발자가 ManyToMany를 선언하는 것을 꺼리는 경향을 볼 수 있습니다. 아마 많은 블로그나 영상에서 ManyToMany는 좋지 못하다고 이야기하므로 그러겠다고 생각됩니다. ManyToMany를 기피하는 이유는 아마 관계 테이블의 변경이 발생하였을 때 변경이 불편하기 때문이라 생각됩니다. 관계 정보에 단순하게 A Entity와 B Entity의 Primary Key만 존재하는 것이 아니라 다른 추가 정보가 들어갈 가능성이 있기 때문이라고 많은 글에서 이야기합니다. 하지만 저는 미래에 일어날지도 모를 가능성 때문에 굳이 좋은 연관관계 표현 방식을 포기해야 하는지 모르겠습니다. ManyToMany를 사용하면 불필요한 Assoc Entity를 선언하지 않아도 됩니다. Entity 입장에서는 N:M 관계인지 1:N 관계인지 중요하지 않습니다. 이것은 데이터베이스 관점에서 중요한 포인트입니다. 그래서 A Entity가 B Entity를 다수 가질 수 있고 B Entity가 A Entity를 다수 가질 수 있는 구조에서 중간에 Assoc Entity가 불필요한 것입니다.
많은 글에서 말하는 Assoc Entity에 새로운 정보가 추가된다면 이것은 단순하게 도메인에 필요한 기능이 변경된 것입니다. 그렇다면 테스트 코드를 변경하고 이 요구사항을 충족하기 위해 기능을 변경하면서 Assoc Entity를 추가하고 관계를 ManyToMany에서 OneToMany, ManyToOne으로 바꿔주면 되는 것입니다.
혹자는 데이터베이스를 변경하는 것은 어렵기 때문에 미리 변경 가능성을 열어두고 설계해야 한다고 말할 수도 있습니다. 맞는 말입니다. 그래서 관계 테이블이 변경될 가능성이 크다면 미리 변경 가능성을 열어두고 ManyToMany를 선언하지 않을 수도 있습니다. 하지만 그것은 비즈니스 요구사항을 충분히 뜯어보고 고민해본 후 내린 결정이어야 하리라 생각됩니다. 덮어놓고 ManyToMany는 좋지 않은 것이니 불필요한 Assoc Entity를 만들어 연관관계를 맺어줄 필요는 없다고 생각합니다.
그래서 아래와 같이 Board Entity와 Tag Entity의 관계에서는 @ManyToMany를 선언해서 연관관계를 표현해 주었습니다. @JoinTable에 대해서는 JPA를 사용해본 분이라면 아실 테니 설명은 생략하겠습니다.
@ManyToMany(fetch = FetchType.LAZY, cascade = [CascadeType.PERSIST, CascadeType.MERGE])
@JoinTable(
name = "board_tag_assoc",
joinColumns = [JoinColumn(name = "board_id")],
inverseJoinColumns = [JoinColumn(name = "tag_id")],
)
protected val mutableTags: MutableSet<Tag> = tags.toMutableSet()
val tags: Set<Tag> get() = mutableTags.toSet()
여기서 추가로 팁을 주자면 앞서 정의한 도메인에서는 Board가 삭제될 때 Tag는 삭제되지 않길 바라고 있습니다. 왜냐하면 서로 생명주기가 다르기 때문인데요. 그래서 CascadeType.REMOVE를 제외해야 합니다. board_tag_assoc이 삭제되어야 한다고 생각해서 CascadeType.REMOVE를 함께 추가해버리면 Tag Entity도 함께 삭제되니 주의할 필요가 있습니다. CascadeType.REMOVE가 없어도 board_tag_assoc은 삭제됩니다.
중복된 관계를 추가하고 싶지 않다면 Set을 활용하자
위 코드를 자세히 보았다면 눈치챘겠지만 Tag는 Set으로 정의된 것을 볼 수 있습니다. Tag Entity를 보면 알 수 있겠지만 동일한 Key와 Value는 저장될 수 없습니다. 즉, Board에는 하나의 Key와 Value 세트만 입력될 수 있다는 것입니다. 만약 List로 Collection을 선언한다면 addTag함수에서 매번 아래와 같이 기존 Tag에 새로 입력하는 Tag가 존재하는지 여부를 체크해야 할 것입니다.
fun addTag(tag: Tag) {
if (!mutableTags.contains(tag)) {
mutableTags.add(tag)
}
}
하지만 Set Collection을 이용하면 위와 같은 코드는 불필요합니다. 자료구조가 중복된 요소를 알아서 제거해주기 때문입니다. 이렇듯 연관관계를 표현할 때 반드시 List만 사용할 필요는 없습니다. 적절한 자료구조를 선택해서 효율적으로 코드를 작성하면 좋겠습니다.
Value Object
Entity를 이야기할 때 Value Object를 빼고 이야기할 순 없습니다. Value Object에 관한 글 을 보면 Value Object는 식별자가 없이 속성값으로 식별하는 객체를 말합니다. 위에서 정의한 도메인에서도 두 가지 형태의 Value Object를 예로 들어봤습니다.
Embedded
Embedded는 Entity가 가진 Property 들의 공통된 특성을 하나의 객체로 묶어 표현해줄 때 사용할 수 있습니다. Entity와 Entity를 연결해주는 @OneToOne 관계로도 풀 수 있으나 이는 성격이 조금 다른 예라고 볼 수 있습니다. @Embedded는 아래와 같이 @Embedable이 선언된 클래스와 연결해서 사용할 수 있습니다.
@Embeddable
data class BoardInformation(
@Column
val link: String?,
@Column(nullable = false)
val rank: Int,
)
데이터베이스에는 Board 테이블에 link와 rank Column으로 정의되지만 Board Entity에서는 BoardInformation이 가진 link와 rank Property로 표현되기 때문에 평탄하게 표현된 속성을 묶어주는 용도로 사용하기 좋습니다. @Embedable 클래스는 Value Object이기 때문에 값이 중요한 객체입니다. 그래서 Kotlin의 Data class로 사용하기 아주 알맞은 객체이기도 합니다.
ElementCollection
Embedded가 단일 Value Object라면 ElementCollection은 복수의 Value Object를 표현해줄 때 사용합니다. @OneToMany와 유사하지만 다른 점은 @OneToMany는 Entity와 Entity 간의 관계를 나타낼 때 사용하고 @ElementCollection은 Entity와 Value Object 간의 관계를 나타낼 때 사용합니다. 즉 @ElementCollection에 정의된 Value Object는 Entity의 생명주기와 함께하며 식별자를 가지지 않는 것이 특징입니다. 왜냐하면 Value Object는 값이 곧 식별자이기 때문입니다.
위에 정의한 도메인에서는 게시판의 댓글인 Comment를 Value Object로 표현해보았습니다. Comment를 Value Object로 봐도 되는지에 대해서는 논란의 여지가 있겠지만 @ElementCollection을 보다 쉽게 소개하기 위한 용도로 정의한 것이니 실무에서 사용하는 것과 같이 깊이 생각은 하지 않았으면 좋겠습니다.
@Embeddable
data class Comment(
@Column(length = 3000)
val content: String,
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(nullable = false)
val writer: User,
)
@ElementCollection의 또 하나 특징은 Collection의 요소가 변경될 때마다 아래와 같이 모든 데이터를 지웠다가 새롭게 등록한다는 것입니다. Value Object는 Entity의 하나의 Property에 불과하다는 점과 식별자가 따로 없다는 점에서 이러한 동작 방식은 어색하지 않습니다. 객체 관점에서는 문제가 없으나 데이터베이스 관점에서는 문제가 될 수 있으므로 이 부분을 염두에 두고 설계하면 좋겠습니다.
@DataJpaTest(showSql = true)
class UserRepositoryTest {
@Autowired private lateinit var boardRepository: BoardRepository
@Autowired private lateinit var testEntityManager: TestEntityManager
@Test
fun test() {
val user = User("홍길동")
val board = Board("게시판", "내용", BoardInformation(null, 1), user, setOf())
board.addComment(Comment("내용", user))
testEntityManager.persist(user)
testEntityManager.persist(board)
testEntityManager.flush()
testEntityManager.clear()
val actual = boardRepository.getReferenceById(board.id)
actual.addComment(Comment("내용2", user))
testEntityManager.merge(actual)
testEntityManager.flush()
}
}
Hibernate:
insert
into
"user"
(name, id)
values
(?, ?)
Hibernate:
insert
into
board
(content, created_at, link, rank, title, "writer_id", id)
values
(?, ?, ?, ?, ?, ?, ?)
Hibernate:
insert
into
board_comment
(board_id, content, "writer_id")
values
(?, ?, ?)
Hibernate:
select
board0_.id as id1_0_0_,
board0_.content as content2_0_0_,
board0_.created_at as created_3_0_0_,
board0_.link as link4_0_0_,
board0_.rank as rank5_0_0_,
board0_.title as title6_0_0_,
board0_."writer_id" as writer_i7_0_0_
from
board board0_
where
board0_.id=?
Hibernate:
select
mutablecom0_.board_id as board_id1_1_0_,
mutablecom0_.content as content2_1_0_,
mutablecom0_."writer_id" as writer_i3_1_0_
from
board_comment mutablecom0_
where
mutablecom0_.board_id=?
Hibernate:
delete
from
board_comment
where
board_id=?
Hibernate:
insert
into
board_comment
(board_id, content, "writer_id")
values
(?, ?, ?)
Hibernate:
insert
into
board_comment
(board_id, content, "writer_id")
values
(?, ?, ?)
Cascade
JPA 뿐만아니라 많은 ORM에서 영속성 전이(Cascade)를 활용할 수 있도록 기능을 제공해줍니다. Cascade를 활용하면 비즈니스 코드를 상당히 줄일 수 있습니다. 물론 잘 활용하기 위해서는 도메인에 대한 깊은 이해가 필요한 것도 사실입니다.
Entity를 정의하다 보면 하나의 Entity의 생명주기에 다른 Entity도 영향을 받아야 하는 경우가 종종 있습니다. 예제로 든 사용자가 삭제되면 해당 사용자가 작성한 모든 게시판이 삭제되어야 한다와 같이 말입니다. 만약 이 스토리를 만족시키기 위해 코드를 작성할 때 Cascade를 활용하지 않으면 어떤 코드가 작성될지 아래 서비스 코드를 보겠습니다.
@Service
class UserService(
private val userRepository: UserRepository,
private val boardRepository: BoardRepository,
) {
@Transactional
fun delete(id: UUID) {
val user = userRepository.getReferenceById(id)
boardRepository.deleteAll(user.boards)
userRepository.delete(user)
}
}
위 코드와 같이 사용자를 삭제하기 위해서는 게시판이 삭제되어야 하므로 게시판을 먼저 삭제하는 코드가 필요합니다. 하지만 Cascade를 활용하면 위 코드를 훨씬 단순하게 바꿀 수 있습니다.
@Service
class UserService(
private val userRepository: UserRepository,
) {
@Transactional
fun delete(id: UUID) {
userRepository.deleteById(id)
}
}
Entity를 새롭게 추가하는 경우에도 Cascade를 활용하면 좋습니다. 게시판에 태그를 추가하는 스토리를 구현해보겠습니다. Cascade가 없다면 아래와 같이 구현할 수 있을 것입니다.
@Transactional
fun addTag(id: UUID, command: TagCreationCommand): Board {
val tag = tagRepository.findByKeyAndValue(command.key, command.value)
.orElseGet {
tagRepository.save(command.toEntity())
}
val board = boardRepository.getReferenceById(id)
board.addTag(tag)
return board
}
태그를 먼저 영속화한 다음에 게시판에 태그를 추가해주는 방식으로 해주어야 합니다. 하지만 Cascade를 활용하면 태그를 영속화해주는 코드가 필요 없습니다.
@Transactional
fun addTag(id: UUID, command: TagCreationCommand,): Board {
val tag = tagRepository.findByKeyAndValue(command.key, command.value)
.orElse(command.toEntity())
val board = boardRepository.getReferenceById(id)
board.addTag(tag)
return board
}
이렇듯 Cascade를 활용하면 많은 코드를 생략할 수 있습니다. 코드를 생략함으로써 명시적이지 않으니 좋지 않은 것이 아니냐는 생각이 들 수 있습니다. 하지만 저는 ORM을 사용하는 순간 명시적이지 않은 동작은 수없이 많기 때문에 그런 우려라면 ORM사용을 다시 검토해보아야 한다고 생각합니다. 오히려 도메인에 대한 충분한 이해를 바탕으로 ORM이 제공해주는 기능을 충분히 활용한다면 번거롭고 복잡한 코드를 작성하지 않고 간단한 코드로도 원하는 기능을 충분히 수행할 수 있을 것입니다.
마치며
지금까지 Kotlin을 이용하여 JPA Entity를 정의할 때 참고하면 좋을 만한 여러 가지 팁들을 소개해보았습니다. JPA 사용법에 대한 내용을 다루는 것이 아니라 다소 생략된 내용이 많이 있지만 Kotlin으로 Entity를 정의할 때 도움이 되었으면 하는 바람입니다. 사실 Entity를 정의하면서 이렇게까지 고민해야 하나 싶은 생각도 듭니다. 하지만 우리가 조금만 생각하고 Entity를 정의하면 애플리케이션의 복잡도를 상당히 낮출 수 있습니다. 억지스러운 구현을 위해 코드들 이리저리 우회하는 형태로 작성하지 않기 때문입니다.
위 고민이 단순히 Entity를 이쁘게 작성하기 위한 팁이 아니라 우리의 제품을 위한 코드가 덜 복잡하고 더 안정적으로 기능이 동작하도록 작성되어서 사용자에게 제품의 가치를 보다 잘 전달할 수 있도록 하기 위한 노력임을 알아봐 주셨으면 합니다.
위에서 예시로 보여준 전체 코드는 Kotlin JPA Entity 예제코드 에 가면 볼 수 있습니다.
긴 글 읽어주셔서 감사합니다.
참고
- https://kotlinlang.org/docs/home.html
- https://docs.jboss.org/hibernate/orm/current/userguide/html_single/Hibernate_User_Guide.html
스포카에서는 “식자재 시장을 디지털화한다” 라는 슬로건 아래, 매장과 식자재 유통사에 도움되는 여러 솔루션들을 개발하고 있습니다.
더 나은 제품으로 세상을 바꾸는 성장의 과정에 동참 하실 분들은 채용 정보 페이지를 확인해주세요!