
안녕하세요. 키친보드 팀의 백엔드 프로그래머 남경호입니다.
최근 키친보드 팀에서는 정비기간을 마친 후 처음으로 제품 개발을 위한 프로젝트를 성황리에(?) 마쳤습니다. 약 7주간 진행했던 이 프로젝트는 키친보드가 제공하던 기존 기능과는 전혀 다른 성격의 기능을 제공하기 위한 프로젝트였습니다. 그러다 보니 개발할 내용도 많고 프로젝트 일정도 넉넉하지 않아 말도 많고 탈도 많았던 프로젝트였던 것 같습니다 ^^;;
아무튼! 이 글에서는 이번 프로젝트에서 새롭게 개발했던 수많은 기능 중에 백엔드 챕터에서 가장 중요하게 생각하고 고민거리와 이슈도 많았던 주문서 도메인을 개발하면서 겪었던 이야기를 공유해드리고자 합니다.
주문서 도메인?
키친보드 서비스는 요식업을 하는 매장과 해당 매장에 식자재를 납품해주는 거래처를 세련되게 연결해주는 서비스입니다. 이전까지는 비용관리에 초점을 맞추었다면 새롭게 개발한 기능은 매장이 거래처에 식자재 주문을 더욱 편리하게 할 수 있도록 해주는 것입니다. 그래서 매장이 앱을 통해서 거래처에 주문서를 전달하면 거래처는 해당 주문서를 받아서 납품할 물품을 확인하고 배송해주는 형태로 운영됩니다. 여기서 말하는 ‘주문서’가 이 글에서 소개할 주문서 도메인 입니다.
유저 스토리
주문서 도메인을 개발하기 위한 주요 유저 스토리는 다음과 같습니다. 아래에 적힌 유저 스토리는 모든 스토리는 아니고 이번 글에서 적을만 한 내용 중 중요한 것들만 적어보았습니다.
- 매장은 식자재 배송을 받기 위해 거래처에 주문서를 접수한다.
- 매장은 마감되지 않은 주문서의 주문서를 수정할 수 있다.
- 매장은 마감되지 않은 주문서의 경우 주문을 취소할 수 있다.
- 매장은 자신이 주문한 주문서 목록을 조회할 수 있다.
- 거래처는 접수된 주문서가 특별한 문제 없이 배송할 수 있으면 주문을 마감한다.
- 거래처는 접수된 주문서를 배송할 수 없는 경우 주문을 취소할 수 있다.
- 거래처는 접수된 주문서에 일부 품목의 변경이 필요한 경우 주문서를 수정할 수 있다.
- 거래처는 자신에게 주문된 주문서 목록을 조회할 수 있다.
- 관리자는 접수된 주문서의 일부 품목의 변경이 필요한 경우 주문서를 수정할 수 있다.
- 관리자는 모든 매장과 거래처의 주문서를 조회할 수 있다.
- 시스템은 주문서의 변경 사항이 발생하면 매장과 거래처에 변경 내용을 알린다.
- 시스템은 주문서의 모든 변경 사항을 기록한다.
- 시스템은 사용자가 수정하려고 하는 정보가 다른 사용자에 의해 변경된 경우 수정할 수 없도록 한다.
생명주기
위에서 정의된 유저 스토리를 기반으로 주문서의 생명주기를 다이어그램으로 표현하면 아래와 같습니다.
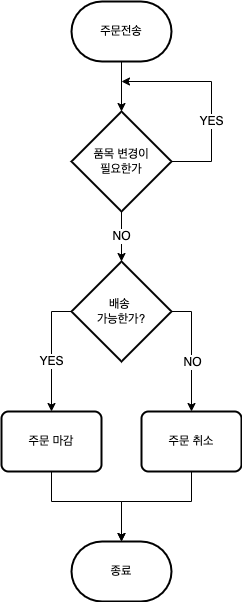
- 매장은 주문정보를 입력하여 거래처에 주문서를 접수합니다.
- 거래처/매장/관리자는 접수한 주문서에 수정할 항목이 있는지 확인합니다. 수정할 항목이 있다면
3번으로 이동합니다. 수정할 항목이 없다면4번으로 이동합니다. - 주문서를 수정합니다. 수정 후
2번으로 이동합니다. - 거래처는 접수된 주문서가 배송 가능한지 확인합니다. 배송이 가능하다면
5번으로 이동합니다. 배송이 불가능하다면6번으로 이동합니다. - 주문서를 마감합니다.
- 주문서를 취소합니다.
- 종료합니다.
고민거리
주문서 도메인의 유저 스토리를 보며 개발할 것들을 정리하고 설계하면서 여러 가지 고민거리들이 있었습니다. 그래서 개발을 시작하기 전 함께 고민하고 결정한 것들을 이야기해 보겠습니다.
여러 사용자가 동일한 주문서를 동시에 수정하면?
유저 스토리를 처음 보았을 때 가장 우려되었던 부분이 주문서의 수정이 주문을 접수한 매장뿐만 아니라 거래처와 관리자 모두 주문서를 수정할 수 있다는 것이었습니다. 커머스 도메인을 다루어보신 분들이라면 아마 같은 걱정을 해보셨을 텐데요. 주문한 사용자는 자기도 모르게 주문서가 수정된다면 참 당황스러울 것이고 이는 곧 CS로 이어지게 됩니다. 거기다 주문을 수정하는 주체가 주문한 사용자 외에 다른 사용자도 가능하므로 동시에 주문서를 수정하게 된다면 의도치 않게 주문서 데이터가 변경될 위험성이 있습니다. 만약 동시에 주문데이터 수정이 발생해서 주문서 정보의 최종 상태가 의도치 않게 변경된다면 CS 처리도 상당히 어려워질 것이고 매번 개발자가 데이터 정합성을 맞춰줘야 하는 상황이 생길 것입니다. (아래부터는 이러한 이슈를 간단하게 동시성 이슈라고 부르겠습니다.)
좀 더 이해가 쉽도록 다이어그램으로 설명해보겠습니다.
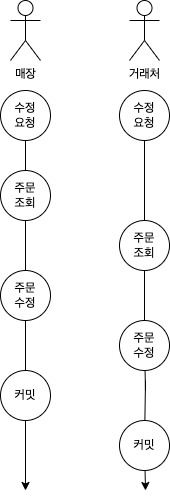
위 그림과 같이 매장과 거래처가 동시에 수정을 요청하였다고 가정해보겠습니다. 매장과 거래처가 수정요청을 동시에 수행하였고 문제없이 처리되었지만, 매장이 수정한 정보는 온데간데없고 거래처가 수정한 정보만 주문서에 반영된 것을 보게 될 것입니다. 매장 입장에서는 당황스럽겠죠?
그래서 저희가 주문서 도메인을 설계할 때 동시성 이슈 즉, 주문서의 수정이 동시에 수정하는 경우 수정이 되지 않도록 방지하여 만약 매장이 주문서를 수정하고자 할 때 거래처가 주문서를 수정한 경우 수정이 된 것을 매장이 알 수 있도록 조치하였습니다. 이러한 조치를 위해 어떤 방법을 채택하였을까요?
데이터베이스의 비관적 잠금
가장 먼저 제시되었던 의견은 바로 RDBMS의 비관적 잠금을 활용하는 것이었습니다. 비관적 잠금은 여러 사용자가 동시에 특정 레코드에 대한 수정요청이 들어오는 경우 데이터베이스의 잠금 기능을 이용하여 요청이 들어온 순서대로 수정사항을 처리하도록 하여서 원치 않게 데이터가 변경되지 않도록 방지하는 방법을 말합니다.
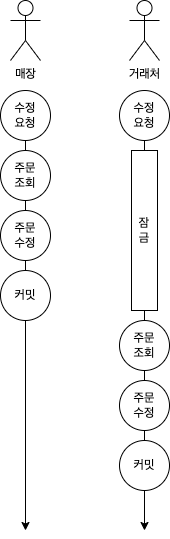
하지만 비관적 잠금은 일반적인 커머스에서 동시에 동일 상품에 대한 주문 시 재고차감과 같은 상황에서는 도움이 될진 몰라도 저희가 수행하고자 하는 주문서의 품목 수정에는 도움이 되지 않았습니다. 왜냐하면 매장이 주문서의 정보를 수정했는데 거래처가 이를 인지하지 못하고 주문서 정보를 덮어씌워 버리기 때문입니다.
데이터베이스의 낙관적 잠금
비관적 잠금으로 인해 사용자가 인지하지 못한 상태로 주문서가 덮어씌워져 버리는 것이 문제라면 낙관적 잠금을 통해서 다음 사용자가 수정을 못 하도록 막으면 되지 않을까 하는 의견이 제시되었습니다. 낙관적 잠금은 데이터베이스에 잠금을 걸기보다 version과 같은 속성을 이용하여 동시에 동일한 레코드의 수정이 발생하지 않도록 방지하는 방법을 말합니다.
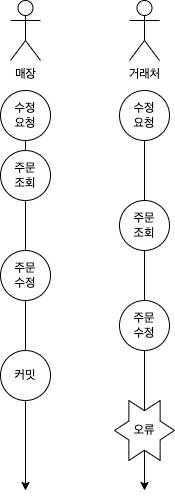
아쉽게도 이 방법도 저희 팀이 해결하고자 하는 문제를 해결하지 못하였습니다. 낙관적 잠금은 서버에 요청이 동시에 들어오는 경우에는 나중에 요청한 사용자가 주문서를 수정할 수 없기 때문에 원하는 바를 충족할 수 있습니다. 하지만 매장이 주문서를 보는 상황에서 주문서 수정을 요청하기 전에 거래처에서 주문서 수정을 완료 처리하게 되면 매장은 주문서를 거래처 수정요청이 완료된 이후에 요청한 후 완료 처리하였기 때문에 낙관적 잠금으로 인해 수정 요청이 거절되지 않고 원하는 주문서 정보로 수정할 수 있을 것입니다. 하지만 거래처에서 수정한 내용을 매장은 몰랐기 때문에 거래처의 수정내용은 비관적 잠금과 마찬가지로 덮어씌워지게 되는 꼴이 되는 것입니다.
어플리케이션의 낙관적 잠금
결국, 데이터베이스의 잠금으로는 저희가 해결하고자 하는 여러 사용자가 같은 주문서를 수정했을 때 사용자가 인지하지 못한 상황에서 주문서의 내용을 덮어씌워 버리는 현상을 막을 방법이 마땅하지 않다고 생각했습니다. 그래서 데이터베이스의 잠금을 이용하는 것이 아닌 애플리케이션의 로직으로 낙관적 잠금과 유사하게 이 문제를 해결하고자 하였습니다.
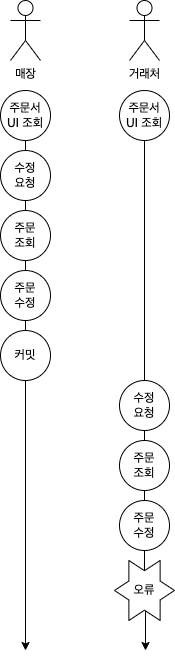
위 다이어그램을 보면 동일한 주문서를 매장과 거래처가 동시에 조회하고 있는 상황에서 매장이 먼저 주문서를 수정 완료한 후 거래처가 주문서를 수정하면 오류가 발생함을 볼 수 있습니다. 즉, 사용자가 최초 조회한 화면과 서버의 데이터가 다른 상태라면 수정내용을 의도하지 않게 덮어씌우지 못하도록 막고 사용자가 다시 주문서를 확인한 후 수정할 수 있도록 의도한 것입니다.
이는 주문서 수정 시도 시 사용자가 예상치 못하게 수정 요청 실패를 경험할 수 있다는 단점이 있지만 동일한 주문서를 조회하는 사용자가 많지 않기에 수정 요청 실패를 마주칠 확률이 낮고 사용자가 의도치 않게 주문서를 수정하는 행위에 대한 위험성이 더 크다고 판단해서 이와 같은 결정을 내리게 되었습니다.
구현
설명은 거창하였지만 사실 구현은 단순합니다.
먼저 단일 주문서 조회 시 내려주는 정보에서 현재 주문서의 버전 정보를 나타내는 revision 속성을 추가하였습니다.
"""
주문서
"""
type OrderSheetField {
"""
ID
"""
id: ID!
"""
리비전
"""
revision: Int!
...생략
}
type Query {
"""
주문서를 조회합니다.
"""
orderSheet(id: UUID!): OrderSheetField!
...생략
}
그리고 수정요청 시 ID뿐만 아니라 revision 정보도 함께 전송하도록 해서 주문서를 수정할 때 버전 정보를 함께 보내도록 하였습니다.
"""
주문서 수정 input
"""
input UpdateOrderSheetInput {
"""
주문서 아이디
"""
id: UUID!
"""
주문서 리비전
"""
revision: Int!
...생략
}
type Mutation {
"""
주문서를 수정합니다.
"""
updateOrderSheet(input: UpdateOrderSheetInput!): UpdateOrderSheet!
...생략
}
도메인 서비스에서는 클라이언트에서 전송받은 ID를 이용하여 주문서정보를 데이터베이스에서 조회하고 주문서를 수정할 때 그 속성을 비교하여 만약 revision 정보가 다르다면 예외를 발생시키고 revision 정보가 같다면 정상적으로 주문서를 수정할 수 있도록 하였습니다.
@Transactional
fun update(auditableData: OrderSheetAuditableData<UpdateOrderSheetData>): OrderSheet {
val data = auditableData.data
val orderSheet = getByIdAndRevision(data.orderSheetId, data.revision)
orderSheet.update(data.toDomainData(auditableData.userType, auditableData.userId))
// ...생략
return orderSheet
}
private fun getByIdAndRevision(id: UUID, revision: Int): OrderSheet {
val orderSheet = orderSheetRepository.findByIdUsingPessimisticLock(id)
.orElseThrow(ErrorMessage.NotFound.ORDER_SHEET)
if (orderSheet.revision != revision) {
throw ConcurrentModificationException("주문서의 revision이 일치하지 않습니다.")
}
return orderSheet
}
getByIdAndRevision함수를 보시면 알 수 있으시겠지만, ID를 이용하여 주문서를 조회할 때 비관적 잠금을 사용했습니다. 그 이유는 비관적 잠금을 하지 않는 경우 만약에 동시에 매장과 거래처가 주문 수정요청을 한다면 revision을 비교할 때 매장과 거래처의 revision이 데이터베이스에 존재하는 주문서의 revision 값과 동일할 것이기 때문에 두 개의 요청 모두 수정 성공할 것이고 이는 앞에서 말한 주문서 정보가 원치 않게 수정되는 문제를 야기하게 될 것이기 때문입니다.
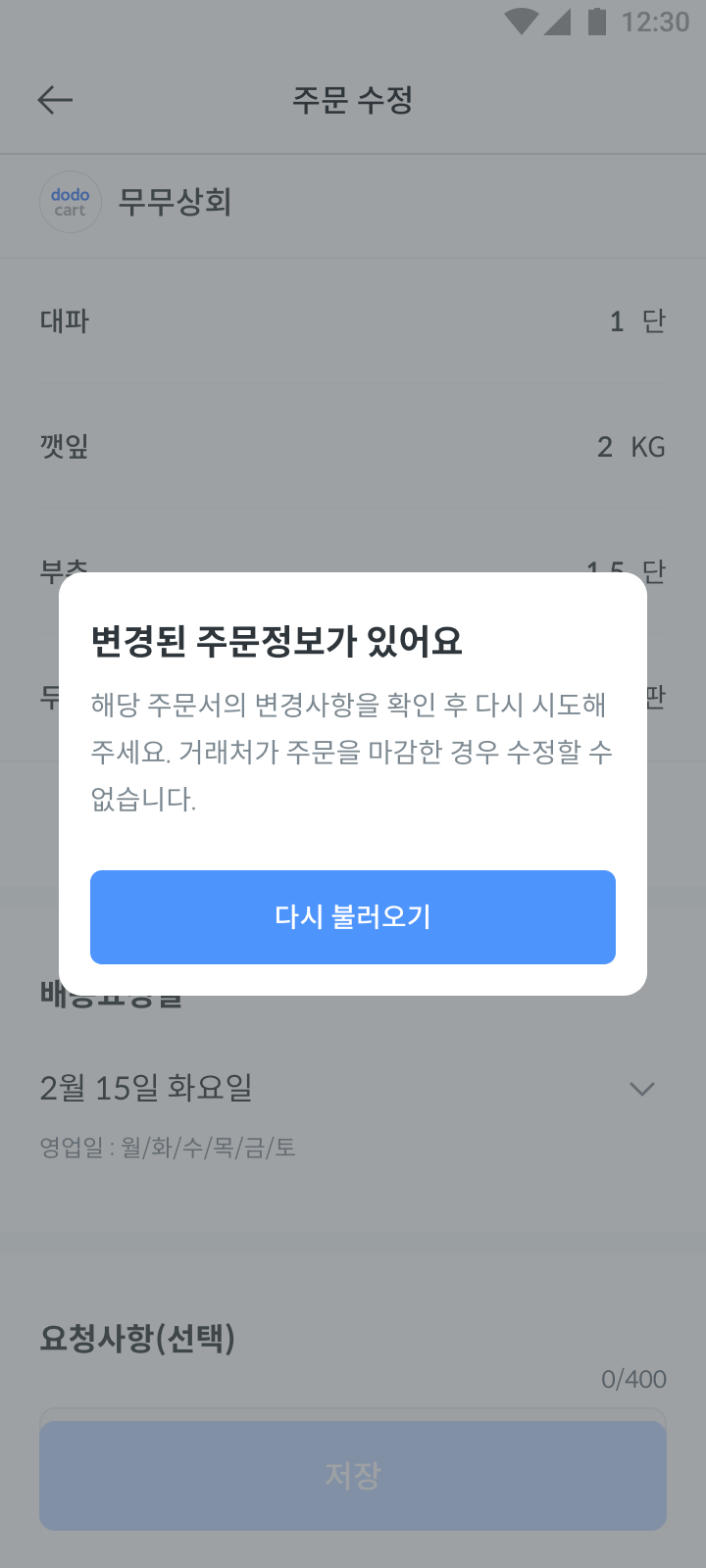
위와 같은 고민을 한 결과 앱 사용자는 만약 수정 요청 시 보고 있던 화면과 데이터베이스의 내용이 달라 수정요청이 변경되면 아래와 같이 변경 사항이 있음을 인지하고 다시 조회하는 화면을 구성할 수 있었습니다.
거래처가 관리하는 품목정보를 수정하면?
다음 고민은 주문서에 입력되는 품목정보를 어떻게 관리하는가였습니다. 거래처는 매장이 주문할 수 있는 품목정보를 가지고 있습니다. 그래서 매장은 이 품목들을 보고 오늘 거래처에 어떤 품목을 몇 개 주문할지 결정한 후 주문서를 제출하게 됩니다.
여기에서 만약 거래처가 품목정보를 수정하게 되면 이전에 주문했던 주문서의 품목은 사용자에게 어떻게 보여야 할까요? 사용자가 원하는 것에 따라 다르겠지만 저희는 주문서가 주문을 위한 용도뿐만 아니라 주문 이력을 관리하는 용도로도 사용된다고 판단했기에 거래처에서 관리하는 품목정보를 변경되었다고 해서 한번 전송된 주문서의 품목정보는 변경되지 않아야 한다고 생각했습니다. 그래서 주문 시 선택하는 품목들은 주문서가 생성되는 시점에 주문서의 품목으로 정보들이 복사되어 저장하도록 구현하였습니다. 그렇게 하면 거래처가 관리하는 품목정보를 참조하고 있지 않기 때문에 거래처 품목정보가 수정되어도 주문서에 반영되지 않을 테니까요.
하지만 여기서 또 하나의 고민거리가 추가됩니다. 바로 주문서의 수정 시 이미 주문한 품목정보를 사용자에게 보여줄 때인데요. 아래 이미지와 같이 주문서의 품목을 수정하려고 할 때 이미 주문한 품목정보들은 주문한 내용이 그대로 반영되어 보여주게 되어있습니다.
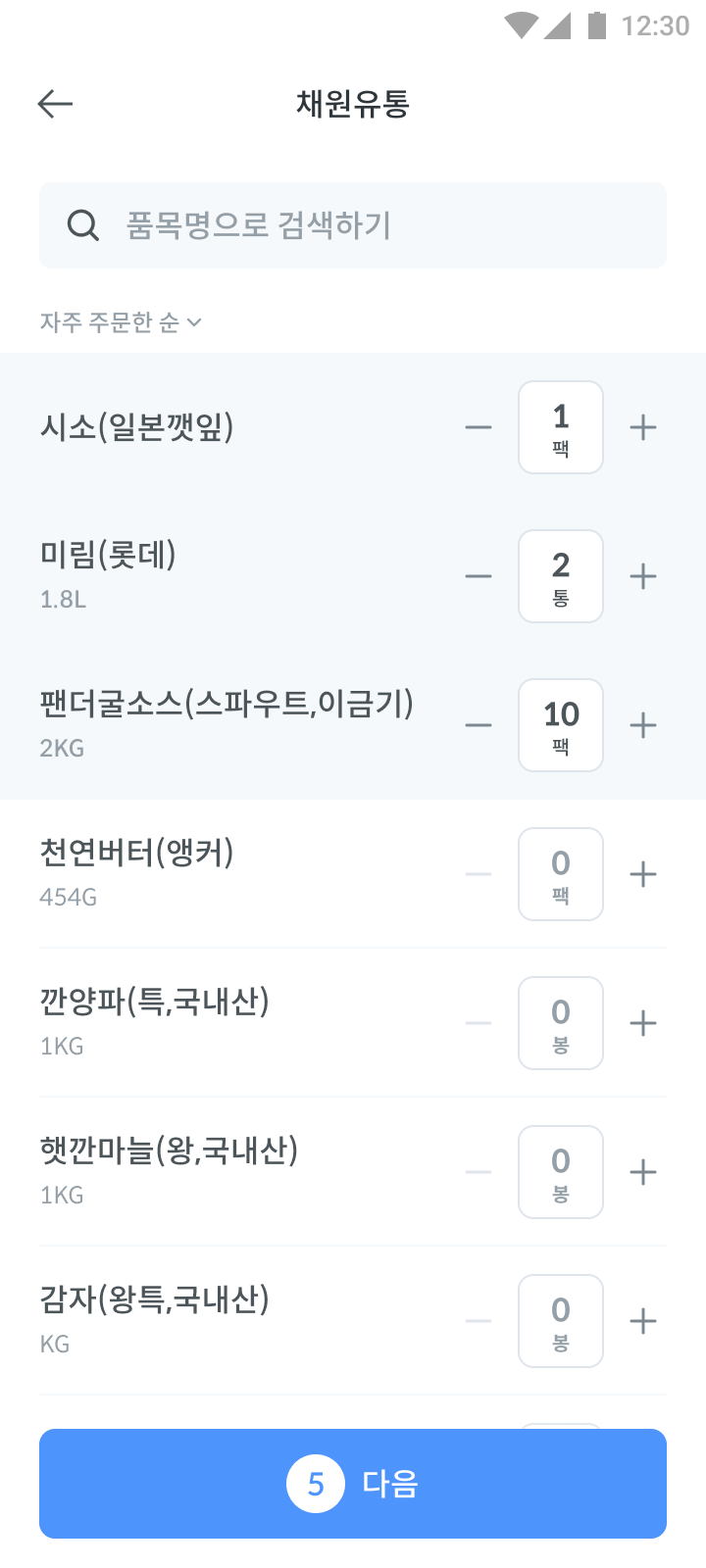
만약 여기에서 채원유통이라는 거래처가 관리하는 품목 중 미림(롯데)이라는 품목이 변경되어 미림(오뚜기)으로 바뀌었다고 가정해보겠습니다. 그러면 위 화면에서 미림(롯데) - 2통으로 표시되던 것이 미림(오뚜기) - 2통으로 표시되어야 할까요? 사용자가 주문한 품목은 미림(롯데)이지 미림(오뚜기)이 아니기 때문에 미림(오뚜기) - 0통으로 표시되는 게 맞아 보입니다. 즉, 거래처 입장에서는 미림(롯데) 품목이 미림(오뚜기)으로 변경되었다고 생각할 수 있지만 미림(롯데) 품목은 삭제되었고 미림(오뚜기) 품목이 새롭게 추가된 것이라고 볼 수 있습니다.
그래서 거래처의 품목관리 기능에서는 수정기능은 없고 추가 및 삭제 기능만 존재하게 되었습니다. 품목을 오입력하였을 때와 같은 상황에서 단순히 품목명을 수정하고 싶은 경우도 생길 것 같은데 수정기능이 없다면 불편하지 않을까? 라는 우려도 있었습니다. 하지만 오입력의 경우도 거래처에서 초기에 품목등록 시 확인 후 삭제 후 새롭게 등록한다면 조금 번거로울 순 있지만 품목 수정기능이 존재함으로 인해 복잡해지는 논리를 단순화함으로써 제품에 대한 신뢰성을 높이는 게 더 나은 선택이라 생각했습니다.
주문서의 이력관리
앞서 소개한 유저 스토리를 보면 아래와 같은 스토리가 있습니다.
시스템은 주문서의 모든 변경 사항을 기록한다.
그래서 주문서의 변경 사항을 저장하기 위해 주문서 이력 Entity를 추가하기로 하였습니다. 여기서 고민은 주문서 상태를 어떻게 저장할 것 인가였습니다.
처음에는 주문서와 동일하게 컬럼을 구성하고 필요한 추가정보를 가진 컬럼을 가진 형태로 만들어보려고 하였습니다. 데이터베이스를 이용하여 이력에 대한 통계를 낸다거나 검색하기에는 용이할 수 있을 테지만 그런 요구사항이 없다면 반드시 컬럼을 동일하게 맞출 필요는 없어 보였습니다. 그래서 저희는 하나의 컬럼에 JSON 형태로 주문서 정보를 저장하는 방법을 채택하였습니다.
다행스럽게도 저희가 사용하는 PostgreSQL에서는 JSON과 JSONB 컬럼 타입이 있습니다. JSON과 JSONB 타입은 JSON 형태의 문자를 저장할 때 varchar 타입과 달리 JSON 포맷인지 유효성 체크를 해줍니다. 그래서 해당 컬럼에는 JSON 데이터가 저장되어있다는 것을 보장할 수 있습니다.
JSON과 JSONB타입의 차이는 JSON은 입력된 값 그대로 문자열로 저장하지만, JSONB 타입은 바이너리 형태로 저장합니다. 그래서 JSONB가 JSON 타입에 비해 쓰기에 대한 부하가 컸지만, 조회 시에는 성능도 더 좋고 JSON 칼럼에 대해 인덱싱도 할 수 있고 operator를 통한 쿼리를 할 수 있기 때문에 유용합니다. (자세한 내용은 공식문서를 참고해주세요)
저희는 그래서 주문서에 대한 스냅숏을 JSONB 컬럼 타입에 저장하도록 아래와 같이 주문서 이력 Entity를 구성하였습니다.
@Entity
class OrderSheetHistory private constructor(
@ManyToOne(fetch = FetchType.LAZY, optional = false)
@JoinColumn(name = "order_sheet_id")
val orderSheet: OrderSheet,
@Type(type = "jsonb")
@Column(nullable = false)
val snapshot: OrderSheetSnapshot,
@Column(nullable = false)
@Enumerated(EnumType.STRING)
val actionType: OrderSheetHistoryActionType,
@Column(nullable = false)
@Enumerated(EnumType.STRING)
val userType: OrderSheetHistoryUserType,
@Column(nullable = false)
val userId: UUID,
) : BaseEntity() {
// ...생략
}
그런다음 주문서의 상태가 변경될 때마다 주문서 이력이 새롭게 추가되도록 하였습니다.
@Entity
class OrderSheet {
// ...생략
@OneToMany(
fetch = FetchType.LAZY,
mappedBy = "orderSheet",
cascade = [CascadeType.PERSIST, CascadeType.MERGE],
)
protected val _histories: MutableList<OrderSheetHistory> = mutableListOf()
val histories: List<OrderSheetHistory> get() = _histories.sortedByDescending { it.createdAt }
fun accept(orderableVendorAccountId: UUID) {
if (_state == OrderSheetState.CANCELED) {
throw IllegalStateException("취소된 주문서는 마감할 수 없습니다.")
}
_state = OrderSheetState.ACCEPTED
_histories.add(
OrderSheetHistory(
orderSheet = this,
actionType = OrderSheetHistoryActionType.ACCEPTED,
userType = OrderSheetHistoryUserType.VENDOR,
userId = orderableVendorAccountId,
),
)
}
fun cancel(managerId: UUID) {
if (_state == OrderSheetState.ACCEPTED) {
throw IllegalStateException("마감된 주문서는 취소할 수 없습니다.")
}
_state = OrderSheetState.CANCELED
_histories.add(
OrderSheetHistory(
orderSheet = this,
actionType = OrderSheetHistoryActionType.CANCELED,
userType = OrderSheetHistoryUserType.STORE,
userId = managerId,
),
)
}
fun update(data: UpdateOrderSheetDomainData) {
_requestedDeliveryDate = data.requestedDeliveryDate
_additionalRequests = data.additionalRequests
replaceProducts(data.products)
_histories.add(
OrderSheetHistory(
orderSheet = this,
actionType = OrderSheetHistoryActionType.UPDATE,
userType = data.updateUserType,
userId = data.updateUserId,
),
)
_updatedAt = OffsetDateTime.now()
}
}
주문서의 도메인 이벤트 처리
주문서 도메인을 개발하면서 주문서의 생성과 상태 변경 또는 수정과 같이 주요 논리를 수행한 후 추가로 보조 논리를 수행해야 하는 요구사항이 있었습니다. 그래서 아래와 같이 처음에 작성하였는데요.
@Service
class OrderSheetService(
private val orderSheetRepository: OrderSheetRepository,
private val chatClient: ChatClient,
private val slackMessageClient: MessageClient,
) {
@Transactional
fun create(auditableData: OrderSheetAuditableData<CreateOrderSheetData>): OrderSheet {
// 주문서 생성 (주요 논리)
val orderSheet = 주문서_생성_로직()
val savedOrderSheet = orderSheetRepository.save(orderSheet)
// 주문 채팅 메시지 전송 (보조 논리)
val chatMessage = 메시지_생성_로직()
chatClient.sendUserOrderMessage(chatMessage)
// 슬렉 알림 (보조 논리)
val slackMessage = 메시지_생성_로직()
slackMessageClient.send(slackMessage)
return savedOrderSheet
}
}
위와 같이 코드를 작성하는 경우 OrderSheetService의 create 함수는 주요 논리 외에 보조 논리로 인해서 그 책임이 점점 커지는 문제가 발생하게 됩니다. 책임이 커지면 일단 먼저 단일책임원칙(SRP)이 위배되는 것은 물론이고 가독성이 떨어지고 수정이 힘들어지니 유지보수성이 떨어질 것이며 의존성이 점점 추가되니 테스트하기에도 어려워지는 그런 거대한 공룡 함수가 탄생하게 되는 것입니다.
그럼 위와 같은 문제를 해결하면서 주요 논리와 보조 논리들을 모두 수행할 방법은 무엇이 있을까요? 바로 이벤트를 활용하는 것입니다. 도메인이 주요 논리를 수행하고 난 후 도메인 이벤트를 발행하게 되고 그 이벤트를 구독하는 이벤트 처리기들이 이벤트를 수신받아서 각자가 가진 보조 논리를 처리하는 방법입니다. Spring에서는 이러한 구현을 더욱 손쉽게 할 수 있도록 Events 메커니즘을 제공해 줍니다. 그래서 아래와 같이 코드를 변경하여 구현하였습니다.
@Service
class OrderSheetService(
private val orderSheetRepository: OrderSheetRepository,
private val eventPublisher: ApplicationEventPublisher,
) {
@Transactional
fun create(auditableData: OrderSheetAuditableData<CreateOrderSheetData>): OrderSheet {
val orderSheet = 주문서_생성_로직()
val savedOrderSheet = orderSheetRepository.save(orderSheet)
val orderSheetSubmittedEvent = 이벤트_생성_로직()
eventPublisher.publishEvent(orderSheetSubmittedEvent)
return savedOrderSheet
}
}
@Component
class SlackMessageEventHandler(
private val slackMessageClient: MessageClient,
) {
@Async
@Transactional(readOnly = true)
@EventListener
fun handle(event: OrderSheetSubmittedEvent) {
val message = 메시지_생성_로직()
slackMessageClient.send(message)
}
}
@Component
class OrderSheetChatHandler(
private val chatClient: ChatClient,
) {
@Async
@Transactional(readOnly = true)
@TransactionalEventListener(OrderSheetSubmittedEvent::class)
fun handle(event: OrderSheetSubmittedEvent) {
val message = 메시지_생성_로직()
chatClient.sendUserOrderMessage(message)
}
}
위와 같이 코드를 변경하게 되면 OrderSheetService는 더 이상 SlackMessageClient와 ChatClient와 같이 보조 논리에 의해 필요한 의존성을 추가하지 않아도 됩니다. 그리고 create 함수는 이제 주요 논리인 주문서를 생성하는 논리와 이벤트를 발행하는 논리 외에는 다른 코드가 존재하지 않으므로 단순하고 간결한 코드를 유지할 수 있습니다. 또한 새로운 보조 논리가 생성된다면 새로운 이벤트 처리기를 추가해서 기능을 확장하면 되기 때문에 훨씬 더 유연하게 기능을 확장할 수 있다는 장점이 있습니다.
이슈
충분히 고민하고 설계했다고 생각하였고, 테스트 케이스도 꼼꼼하게 고민해서 테스트 코드를 작성하였다고 생각하였지만, 이슈가 발생하는 것은 어쩔 수 없나 봅니다.
프로젝트 기간 중 발견되었던 이슈들과 그 이슈들을 어떻게 해결했는지 소개해 드리겠습니다.
JPA의 1차 캐싱
QA 기간 중 아래와 같이 버그 이슈가 생성되었습니다.
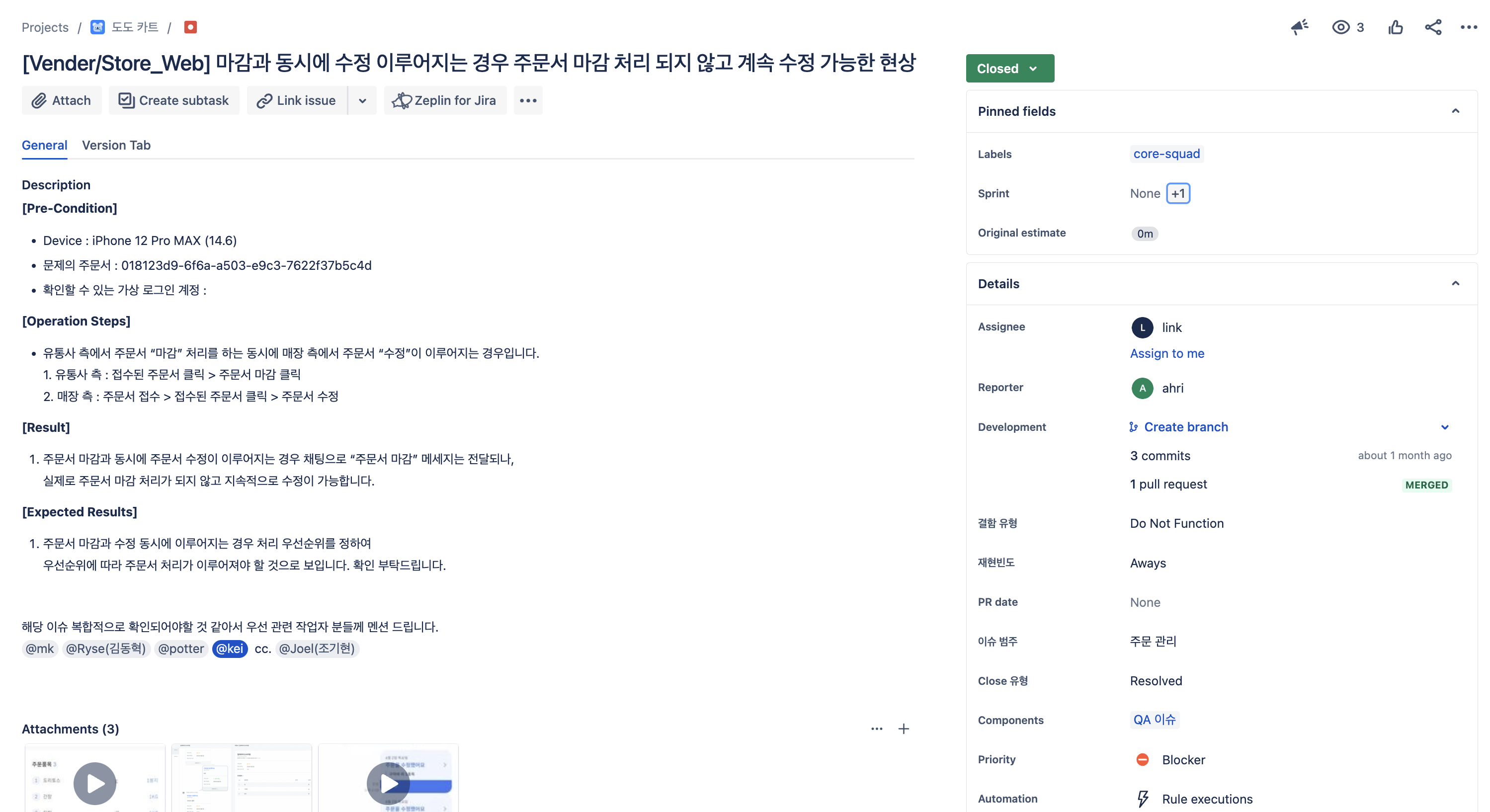
위에서 우려했던 동시성 이슈였습니다. 분명 코드로 보았을 때 문제가 발생하지 않으리라 판단했기에 코드 리뷰에서도 별다른 이견 없이 코드가 병합되었었습니다. 하지만 우려했던 상황은 발생하였고 저희는 이에 대응하기 위해 이슈를 확인하기 시작하였고 그 원인은 JPA의 1차 캐싱이 원인이라는 것을 발견하게 되었습니다.
JPA는 네트워크를 통해서 데이터베이스에 접근하는 비용을 최소한으로 하기 위해서 캐싱을 사용합니다. 1차 캐시는 이런 비용을 줄이기 위해서 하나의 트랜잭션 내에서 Entity를 조회하여 영속 컨텍스트에 로드하면 트랜잭션이 종료될 때까지 로드한 Entity를 재사용합니다. 데이터베이스의 격리 수준에서 Repeatable Read와 비슷한 메커니즘이라고 생각하시면 됩니다.
다시 앞서 동시성 문제를 방지하기 위한 코드를 가져와 보겠습니다.
@Transactional
fun update(auditableData: OrderSheetAuditableData<UpdateOrderSheetData>): OrderSheet {
val data = auditableData.data
val orderSheet = getByIdAndRevision(data.orderSheetId, data.revision)
orderSheet.update(data.toDomainData(auditableData.userType, auditableData.userId))
// ...생략
return orderSheet
}
private fun getByIdAndRevision(id: UUID, revision: Int): OrderSheet {
val orderSheet = orderSheetRepository.findByIdUsingPessimisticLock(id)
.orElseThrow(ErrorMessage.NotFound.ORDER_SHEET)
if (orderSheet.revision != revision) {
throw ConcurrentModificationException("주문서의 revision이 일치하지 않습니다.")
}
return orderSheet
}
이 코드만 보면 하나의 트랜잭션 내에서 한 번만 조회할 것이고 잠금을 통해서 조회하기 때문에 버그 티켓에서 적힌 현상이 발견되지 않으리라 생각됩니다. 하지만 문제는 서비스에서 update 함수를 쓰기 이전에 발생하게 됩니다. 바로 DataFetcher 클래스(REST API라면 Controller 클래스로 이해하시면 됩니다.)에서 주문서의 수정 및 취소, 마감 처리하기 전에 자신의 주문서인지를 확인하는 논리 때문인데요. 이때 조회한 주문서가 1차 캐싱이 되면서 서비스에서 조회할 때는 새롭게 주문서를 조회하는 것이 아니라 캐시 된 주문서를 조회하면서 발생한 것이었습니다.
@DgsComponent
class OrderSheetMutationDataFetcher(
private val orderSheetFacade: OrderSheetFacade,
) {
// ...생략
@DgsMutation
@Secured(MANAGER)
fun cancelOrderSheet(
@InputArgument input: CancelOrderSheetInput,
): DataFetcherResult<CancelOrderSheet> {
val orderSheet = orderSheetFacade.getOrderSheetById(input.id!!)
if (!haveAccessToOrderSheet(orderSheet)) {
throw AccessDeniedException(ErrorMessage.NotFound.ORDER_SHEET.message)
}
return CancelOrderSheetConverter.result(
orderSheetFacade.cancelOrderSheet(
OrderSheetAuditableData(
input.toData(PrincipalProvider.managerId),
OrderSheetHistoryUserType.STORE,
PrincipalProvider.managerId,
),
),
)
}
@DgsMutation
@Secured(OWNER, MANAGER, ORDERABLE_VENDOR)
fun updateOrderSheet(
@InputArgument input: UpdateOrderSheetInput,
): DataFetcherResult<UpdateOrderSheet> {
val orderSheet = orderSheetFacade.getOrderSheetById(input.id!!)
if (!haveAccessToOrderSheet(orderSheet)) {
throw AccessDeniedException(ErrorMessage.NotFound.ORDER_SHEET.message)
}
// ...생략
return UpdateOrderSheetConverter.result(
orderSheetFacade.updateOrderSheet(
OrderSheetAuditableData(
input.toData(),
updateUser.first,
updateUser.second,
),
),
)
}
}
여기서 OrderSheetMutationDataFetcher는 @Transactional을 사용하지 않는데 왜 1차 캐시가 적용되는가에 대한 의문이 드시는 부분이 있을 텐데요. 그 이유는 OSIV(Open Session In View)가 켜져 있기 때문입니다. (OSIV에 대한 자세한 내용은 여기를 참고해주세요) OSIV를 켜두면 HTTP 요청의 시작부터 끝까지 같은 영속성 컨텍스트를 유지합니다. 그래서 1차 캐시가 트랜잭션 범위 밖에 있는 조회도 캐싱 처리한 것이었습니다.
API가 OSIV를 켜두는 것은 데이터베이스의 세션이 오래 유지되기 때문에 위험할 수 있습니다. 다만 OSIV를 활용하면 지연 로딩을 적극적으로 활용할 수 있고 현재 저희가 사용하고 있는 Graphql의 Field Resolver에서 지연 로딩을 활용하면 불필요한 쿼리를 호출하지 않도록 최적화할 수 있기 때문에 OSIV를 켜두는 선택을 하였습니다.
그럼 이 이슈를 어떻게 해결할 수 있을까요? 저희는 2가지 안을 생각했습니다.
DynamicUpdate 이용
JPA에서 Entity 변경을 저장할 때 기본적으로는 아래와 같이 변경 사항이 발생해도 모든 컬럼값에 대해 변경 요청 쿼리를 실행시킵니다.
@Entity
class Person(
@Id
val id: UUID,
val name: String,
var age: Int
)
@Service
class PersonService(
private val personRepository: PersonRepository,
) {
@Transactional
fun gettingOld(id: UUID) {
val person = personRepository.findById(id).orElseThrow()
person.age += 1
}
}
update person set name=?, age=? where id=?
하지만 @DynamicUpdate를 선언해주면 아래와 같이 변경 사항에 대한 수정 쿼리가 실행됩니다.
@Entity
@DynamicUpdate
class Person(
@Id
val id: UUID,
val name: String,
var age: Int
)
@Service
class PersonService(
private val personRepository: PersonRepository,
) {
@Transactional
fun gettingOld(id: UUID) {
val person = personRepository.findById(id).orElseThrow()
person.age += 1
}
}
update person set age=? where id=?
이와같이 변경사항만 수정하는 쿼리가 실행된다면 위 버그 티켓에서 발생하는 현상인 주문서의 수정과 동시에 주문서를 마감하는 경우 주문서의 수정이 주문서의 마감에는 영향을 미치지 않도록 할 수 있습니다. 왜냐하면 주문서의 수정은 주문서의 주문상태의 변화는 일으키지 않고 주문서의 품목정보와 그 외 정보들만 수정하고 주문서의 마감은 주문서의 주문상태만 변경하기 때문입니다.
하지만 DynamicUpdate는 현재 가진 문제를 해결하는 것처럼 보일 순 있어도 근본적으로 동시에 수정요청에 대한 원치않는 값의 변경문제는 그대로 가지고 있기 때문에 채택하기 어려웠습니다. 그리고 DynamicUpdate 설정은 JPA가 Entity의 변경을 감지하고 저장할 때 변경사항을 계산해서 동적으로 쿼리를 생성해 주기때문에 DynamicUpdate 설정없이 Entity 수정 쿼리를 수행하는것보다 수행속도가 떨어진다는 문제점도 함께 가지고 있습니다.
1차 캐시를 사용하지 않는 방법
위 방법을 사용할 수 없다면 다음으로 시도해볼 수 있는 것은 1차 캐시를 사용하지 않는 방법입니다. 사실 Primary Key인 ID를 이용하여 레코드를 조회하는 것은 데이터베이스 입장에서는 비용이 큰 쿼리라고 보기 힘듭니다. 비록 어플리케이션 내에서 캐싱된 데이터를 조회하는 것이 성능적인 측면에서는 훨씬 이득이 많겠지만 지금과 같이 예외적인 상황에서는 오히려 캐시는 독이될 수 있습니다. (캐시는 모든 악의 근원이라는 글을 한번 읽어보시면 좋을 것 같습니다.)
그래서 저희는 주문서를 조회할때 필요한경우 1차 캐시를 사용하지 않도록 하는 기능을 추가하였습니다.
fun <T, Q : AbstractJPAQuery<T, Q>> AbstractJPAQuery<T, Q>.pessimisticWriteLocked(): Q {
return setLockMode(LockModeType.PESSIMISTIC_WRITE)
.setHint(
"org.hibernate.cacheable",
false, // <----------------------- 여기
)
.setHint(
"javax.persistence.lock.timeout",
10000,
)
}
해당 함수를 Repository에서는 아래와 같이 사용합니다.
interface QOrderSheetRepository {
fun findByIdUsingPessimisticLock(id: UUID): Optional<OrderSheet>
// ...생략
}
class QOrderSheetRepositoryImpl(
private val jpaQueryFactory: JPAQueryFactory,
) : QOrderSheetRepository, QuerydslRepositorySupport(OrderSheet::class.java) {
override fun findByIdUsingPessimisticLock(id: UUID): Optional<OrderSheet> {
return Optional.ofNullable(
jpaQueryFactory.selectFrom(orderSheet)
.where(orderSheet.id.eq(id))
.pessimisticWriteLocked()
.fetchFirst(),
)
}
// ...생략
}
다시 서비스 코드를 보면 서비스의 코드는 변경된 것이 없지만 더이상 JPA의 1차 캐시를 사용하지 않게 된 것입니다.
private fun getByIdAndRevision(id: UUID, revision: Int): OrderSheet {
val orderSheet = orderSheetRepository.findByIdUsingPessimisticLock(id)
.orElseThrow(ErrorMessage.NotFound.ORDER_SHEET)
if (orderSheet.revision != revision) {
throw ConcurrentModificationException("주문서의 revision이 일치하지 않습니다.")
}
return orderSheet
}
해당 코드를 적용 후 APM을 통해서 실제 쿼리가 어떻게 전송되는지 확인해보았습니다.
이전에는 아래와 같이 한 번의 쿼리가 실행되었지만

select * from order_sheet ordersheet0_ where ordersheet0_.id=?
변경 코드를 적용하고 난 후 아래와 같이 2번의 쿼리가 실행되는 것을 볼 수 있습니다. 2번째에는 비관적 잠금을 사용하였기에 for update가 쿼리에 적혀 있는 것을 볼 수 있습니다.

select * from order_sheet ordersheet0_ where ordersheet0_.id=?
select * from order_sheet ordersheet0_ where ordersheet0_.id=? limit ? for update of ordersheet0_
주문 품목의 버전관리
최초 주문서의 revision을 생성하는 방법은 주문서의 속성들과 주문서에 적힌 품목들의 속성들을 이용하여 생성하는 것이었습니다. 그래서 주문서의 속성값이 변경되면 주문서 조회 시 이전과는 다른 revision 정보를 반환하도록 구성할 수 있었습니다. 하지만 동일한 내용으로 주문서 수정을 요청하면 주문서가 가진 상태들이 변경되지 않았기 때문에 revision 정보는 변경되지 않아야 함에도 revision이 변경되는 이슈를 발견하게 되었습니다. 원인을 파악해보니 바로 주문서가 가진 품목정보가 원인이었는데요.
저희는 주문서에서 주문서는 Entity로 주문서가 가진 품목들을 Value Object로 생각하고 도메인 모델을 구성하였습니다. Entity와 Value Object의 차이를 간단하게 먼저 설명하고 이야기를 이어 나가겠습니다.
Entity
우리말로 참조 객체라고 해석되기도 하며 식별성과 연속성을 가진 객체를 말합니다.
식별성
식별성을 가진 객체란 식별자를 가진 객체라고 할 수 있는데요. 사람을 예로 들면 주민등록 번호가 통장을 예로 들면 통장번호가 대표적인 식별자라고 할 수 있을 것입니다.
연속성
Entity는 자신의 생명주기 동안에 형태와 내용이 변경될 수 있습니다. 사람을 예로 들면 이름이나 성별(?), 출생지 등은 생애주기 동안에 언제든지 바뀔 수 있습니다. 하지만 주민등록 번호는 한번 생성되고 나면 변경되지 않습니다. 여기에서 이름이나 성별, 출생지 등이 변경되어도 동일한 사람임을 추적할 수 있는 성질이 연속성입니다.
Value Object
우리말로 번역하면 값 객체라고 부를 수 있을 것 같습니다. 개념적인 식별성이 없이 도메인의 서술적 측면만을 나타내는 객체를 이야기합니다. 이렇게 정의하면 너무 어려운 것 같아 오브젝트 디자인 스타일 가이드에 적힌 글을 인용해 보겠습니다.
한 아이가 그림을 그릴 때 그 아이는 자기가 고른 펜의 색깔과 펜촉의 두께에 관심이 있을지도 모른다. 그러나 색과 모양이 같은 펜이 두 자루 있다면 아이는 아마 둘 중 어느 것을 사용하고 있는지 신경 쓰지 않을 것이다. 펜을 잃어버려서 펜 꾸러미에서 색깔이 같은 펜을 꺼내 바꿔놓더라도 아이는 펜이 바뀌었는지는 개의치 않고 계속해서 그림을 그릴 것이다.
위인용에서 볼 수 있듯이 Value Object는 객체의 식별성은 중요하지 않고 속성의 값이 중요합니다. 속성의 값이 동일하다면 동일한 객체로 인지하는 것입니다. 그래서 대부분의 경우 Value Object는 식별자가 필요하지 않습니다.
다시 이야기로 돌아오면 주문서는 Entity로 주문서의 품목들은 Value Object로 판단했기 때문에 주문서의 품목은 ID는 중요하지 않고 그 값들이 중요합니다. 그래서 주문서를 수정할 때 품목정보의 변경을 더욱 단순하게 처리하기 위해 모든 품목을 지우고 수정요청이 들어온 값으로 새롭게 넣어주도록 로직을 작성하였습니다.
@Entity
class OrderSheet {
// ...생략
@OneToMany(fetch = FetchType.LAZY, mappedBy = "orderSheet", cascade = [CascadeType.ALL], orphanRemoval = true)
protected val _products: MutableList<OrderSheetProduct> = arrayListOf()
val products: List<OrderSheetProduct> get() = _products.toList()
private fun replaceProducts(dataList: List<ReplaceOrderSheetProductData>) {
_products.clear()
val products = dataList.map {
OrderSheetProduct(
name = it.name,
standard = it.standard,
unit = it.unit,
count = it.count,
orderableVendorProductId = it.orderableVendorProductId,
orderSheet = this,
)
}
this._products.addAll(products)
}
fun update(data: UpdateOrderSheetDomainData) {
_requestedDeliveryDate = data.requestedDeliveryDate
_additionalRequests = data.additionalRequests
replaceProducts(data.products)
_histories.add(
OrderSheetHistory(
orderSheet = this,
actionType = OrderSheetHistoryActionType.UPDATE,
userType = data.updateUserType,
userId = data.updateUserId,
),
)
_updatedAt = OffsetDateTime.now()
}
// ...생략
}
이렇게 로직을 구성하여도 문제없다고 판단한 이유는 주문서의 품목들은 ID가 중요하지 않고 값이 동일하다면 동일한 품목정보로 인식하기 때문에 수정 시마다 품목 정보를 모두 지우고 새롭게 생성하여 ID가 바뀌게 되더라도 문제가 없다고 판단했기 때문입니다. 만약 이렇게 구성하지 않고 기존 데이터와 새롭게 추가된 데이터를 비교해서 수정할 품목은 수정하고 삭제할 품목은 삭제하고 추가할 품목은 삭제하도록 코드를 작성한다면 위와 같이 간결한 코드는 작성하기 힘들 것입니다. 그렇다고 성능적으로 엄청나게 뛰어나게 이점을 가져가지도 않을 것이라고도 생각했습니다.
다만 이로인해 이슈가 발생하였습니다. revision을 생성할 때 주문서와 품목정보의 프로퍼티들을 이용한다고 말씀드렸었는데요.
@Entity
class OrderSheet {
// ...생략
val revision: Int
get() {
var result = Objects.hashCode(id)
result = 31 * result + requestedDeliveryDate.hashCode()
result = 31 * result + (additionalRequests?.hashCode() ?: 0)
result = 31 * result + _state.hashCode()
result = 31 * result + storeId.hashCode()
result = 31 * result + orderableVendorId.hashCode()
result = 31 * result + _products.sumOf { it.revision }
return result
}
}
@Entity
class OrderSheetProduct {
// ...생략
val revision: Int
get() {
var result = Objects.hashCode(id)
result = 31 * result + name.hashCode()
result = 31 * result + (standard?.hashCode() ?: 0)
result = 31 * result + unit.hashCode()
result = 31 * result + count.hashCode()
result = 31 * result + orderableVendorProductId.hashCode()
return result
}
}
위 코드에서 OrderSheetProduct의 revision을 생성할 때 id 프로퍼티가 활용되는 것을 볼 수 있습니다. 하지만 앞에서 말씀드렸다시피 주문서의 수정 시 품목정보는 모두 지운 후 수정요청을 받은 품목정보로 새롭게 다시 등록한다고 말씀드렸었습니다. 그래서 id가 매 수정 시마다 변경되게 되므로 주문서의 revision은 변경 사항이 없이 수정하더라도 변경되게 된 것입니다.
그래서 변경 사항이 없이 수정하는 경우 revision을 생성할 때 id 프로퍼티는 활용하지 않도록 변경함으로써 해당 이슈는 해결하게 됩니다.
@Entity
class OrderSheetProduct {
// ...생략
val revision: Int
get() {
var result = 31 * name.hashCode()
result = 31 * result + (standard?.hashCode() ?: 0)
result = 31 * result + unit.hashCode()
result = 31 * result + count.hashCode()
result = 31 * result + orderableVendorProductId.hashCode()
return result
}
}
hashCode
앞서 주문서의 revision을 생성하는 코드를 보셔서 아시겠지만 revision의 정보를 생성할 때 hashCode를 사용하였습니다. Java에서 hashCode는 객체를 식별하는 하나의 정숫값으로 주로 HashSet, HashMap, HashTable 등에서 객체의 값에 대한 동등성 비교 시 많이 활용됩니다.
hashCode를 사용한 이유
hashCode를 사용한 이유는 다음과 같습니다.
고정된 크기
먼저 hashCode는 해시 알고리즘을 사용하게 깨문 임의 데이터를 고정된 크기의 데이터로 변환할 수 있기 때문에 주문서 정보의 양에는 상관없이 고정된 크기의 리비전 값을 반환할 수 있을 것이라 기대했습니다.
내장 함수
hashCode는 언어에서 내장된 함수이기 때문에 라이브러리 의존성은 Entity가 추가로 가지지 않아도 되어 복잡성을 줄일 수 있으리라 생각했습니다.
동등성 보장
앞서 말한 바와 같이 hashCode는 HashSet, HashMap, HashTable 등에서 객체의 값에 대한 동등성 비교 시 활용되고 있습니다. 그렇기 때문에 같은 속성을 가진 주문서라면 동일함을 보장해 줄 것이라 기대했습니다.
그래서 아래와 같이 revision을 구현하였고 테스트 코드에서도 실제 QA 서버에서 배포하여 QA 진행 중에도 문제없이 잘 동작하였습니다.
@Entity
class OrderSheet {
// ...생략
val revision: Int
get() {
var result = Objects.hashCode(id)
result = 31 * result + requestedDeliveryDate.hashCode()
result = 31 * result + (additionalRequests?.hashCode() ?: 0)
result = 31 * result + _state.hashCode()
result = 31 * result + storeId.hashCode()
result = 31 * result + orderableVendorId.hashCode()
result = 31 * result + _products.sumOf { it.revision }
return result
}
}
@Entity
class OrderSheetProduct {
// ...생략
val revision: Int
get() {
var result = 31 * name.hashCode()
result = 31 * result + (standard?.hashCode() ?: 0)
result = 31 * result + unit.hashCode()
result = 31 * result + count.hashCode()
result = 31 * result + orderableVendorProductId.hashCode()
return result
}
}
하지만 어느 날 프론트앤드 개발자분께서 개발 서버의 주문서의 수정을 수행할 수 없다는 이슈를 제기해 주셨습니다. 코드에 변경하지 않았기 때문에 QA에도 문제가 없어서 혹시 연동 시 문제가 발생하였는지 확인을 하던 중 동일한 주문서 ID로 조회하는데 조회 시마다 revision 값이 바뀌어서 조회되는 것을 확인하게 되었습니다. 당시에 신기하다고 생각했던 건 2개의 값이 서로 번갈아 가면서 조회되는 것이었습니다. 원인을 찾던 중 문득 들었던 생각은 최근 개발 서버를 1대에서 2대로 올렸다는 것을 인지하게 되었습니다. 그래서 테스트를 위해 개발 서버를 다시 1대로 줄여보았고 이전과 같이 주문서를 정상적으로 수정할 수 있게 되었다는 것을 확인하게 되면서 결국 revision 정보가 동일한 주문서임에도 불구하고 서버마다 다른 값을 반환하고 있다는 것을 증명할 수 있게 되었습니다.
원인은 무엇이었을까요?
솔직히 말씀드리면 완전히 서버마다 hashCode가 다르게 반환됨을 확인할 수 있는 코드나 문서를 찾지는 못하였습니다. 다만 Object.hashCode에 대한 Oracle 문서에서 어느 정도 힌트는 얻을 수 있었습니다.
Whenever it is invoked on the same object more than once during an execution of a Java application, the hashCode method must consistently return the same integer, provided no information used in equals comparisons on the object is modified. This integer need not remain consistent from one execution of an application to another execution of the same application.
하나의 애플리케이션(서버)이 실행되는 동안 해당 어플리케이션 내에서 hashCode를 호출하는 것은 동등성을 보장해 주지만 다른 애플리케이션(서버)에서 실행된 hashCode까지는 동등성을 보장해 주지 않는다는 것입니다. 즉, hashCode를 구현한 객체마다 다를 수 있지만, 최상위 객체인 Object에서 정해 놓은 바와 같이 어플리케이션 간에 hashCode에 대한 동등성은 보장해 주지 않는다는 의미로 해석할 수 있을 것 같습니다.
그래서 어떻게 해결하였나요?
hashCode를 사용하지 않는다면 다른 해시알고리즘을 사용할 수는 있을 것입니다. 하지만 아쉽게도 다른 해시 알고리즘은 문자열 형태를 띠는 값이 많아 Int 타입을 가진 revision의 스키마 유형을 바꾸는 것은 원치 않았습니다. 그래서 내부 변경에 대한 정보를 반환하면서 Int 타입을 반환할 수 있는 값이 무엇일까 고민하였고 다행히 주문서 도메인이 수정사항이 생길 때마다 이력을 기록한다는 것을 기억하게 되었고 주문상태가 변경되거나 주문서를 수정할 때마다 이력이 새롭게 등록될 것이기 때문에 주문서의 이력 개수를 revision으로 사용하면 좋겠다고 생각하게 되었습니다.
@Entity
class OrderSheet {
// ...생략
@OneToMany(
fetch = FetchType.LAZY,
mappedBy = "orderSheet",
cascade = [CascadeType.PERSIST, CascadeType.MERGE],
)
protected val _histories: MutableList<OrderSheetHistory> = mutableListOf()
val histories: List<OrderSheetHistory> get() = _histories.sortedByDescending { it.createdAt }
val revision: Int get() = _histories.size
}
마치며
한편 이런 간단한 고민거리와 기초적인 지식의 부족으로 인해 이슈가 발생하는 부분에 대해서 말씀드리는 것이 부끄럽기도 합니다. 하지만 저희 팀이 이러한 고민과 이슈를 겪으면서 한층 더 발전했다는 것에 의미를 두고 싶고 혹시나 이 글을 읽으시는 분 중에 저희와 같은 고민을 하거나 이슈를 겪으셨다면 조금이나마 도움이 되었으면 하는 바람이 있습니다. 앞으로도 저희 스포카에서 개발하면서 겪었던 여러 경험을 공유하며 함께 발전해 나가기 위해 더욱더 노력하도록 하겠습니다.
긴 글 읽어주셔서 감사합니다.
스포카에서는 “식자재 시장을 디지털화한다” 라는 슬로건 아래, 매장과 식자재 유통사에 도움되는 여러 솔루션들을 개발하고 있습니다.
더 나은 제품으로 세상을 바꾸는 성장의 과정에 동참 하실 분들은 채용 정보 페이지를 확인해주세요!