
안녕하세요. 스포카 프로그래머 홍민희입니다. 이 글에서는 스포카에서 여러 오픈 소스 프로젝트를 관리하면서 알게 된, 릴리스 프로세스를 정하고 자동화하는 데에 도움이 되는 여러 꿀팁들을 소개하고자 합니다. 오픈 소스를 가정하고 있기는 하지만, 버전 번호를 매겨서 릴리스하는 프로젝트라면 오픈 소스가 아니라도 대부분 적용할 수 있습니다.
스포카에서 관리하는 오픈 소스 프로젝트는 대부분 라이브러리 패키지이거나 CLI 프로그램, 또는 API를 제공하는 서버 소프트웨어로, 다시 말해 프로그램 가능한 인터페이스를 제공합니다. 도도 포인트 같은 서비스처럼 뚜렷한 버전 번호 없이 업데이트를 해서는 안되고, 프로그램 사이의 호환성에 대한 암시를 줄 수 있는 버전 번호를 제공해야 합니다. 따라서 릴리스에 의한 버전 구분이 메인테이너와 이용자 모두에게 뚜렷합니다. 유의적 버전(Semantic Versioning) 같은 규칙이 유용한 까닭도 그러한 배경에 있겠습니다.
새 버전 릴리스는 생각보다 신경 쓸 데가 많습니다. 호환성을 고려해서 적절한 버전 번호를 정해야 하고, 이용자들이 어떤 변화가 있었는지 알 수 있어야 합니다. 라이브러리 패키지라면 패키지 저장소에도 새 버전을 등록한 뒤 타볼을 업로드해야 하고, 애플리케이션이라면 빌드된 실행 바이너리 파일도 함께 올려야 합니다. 릴리스 프로세스는 생각보다 해야 할 부분 과업이 많고, 부분 과업이 많다는 것은 사람이 실수할 기회도 많다는 뜻입니다. 실수를 줄이려면 많은 부분을 자동화하고, 실수하기 어려운 순서로 프로세스를 개선해야 합니다.
다행히, 상당히 많은 실수는 여러 요령을 통해 예방 가능합니다.
체인지로그는 제 때 써두기
이 글에서 제시하는 여러 팁을 잘 활용하기 위해서라도, 체인지로그(changelog)를 잘 남기는 것을 권합니다. (아래에서 제시하는 몇 가지 팁은 체인지로그를 적지 않으면 활용하기 어렵습니다.)
체인지로그는 이용자들이 문제를 겪을 때 특히 활용도가 높습니다. 제품에서 가져다 쓰는 라이브러리의 버전이 올라가면서 자동화된 테스트가 실패하기 시작하거나, 심지어는 배포 직후에 예상치 못하게 오류가 나는 일은 대부분의 현업 프로그래머들이 겪어보는 어려움입니다. 이럴 때 많은 프로그래머들이 사용중인 라이브러리에 최근 어떤 변경이 있었는지 보고 이를 통해 미루어 짐작합니다. 특히 빠르게 문제를 해결해야 하는 상황에서는 그러한 짐작을 할 때 체인지로그가 큰 도움이 됩니다. 하다못해 일단 이전에 쓰던 버전으로 되돌리거나 최신 버전을 쓰지 않도록 버전을 고정하는 결정이라도 하려면 체인지로그가 제공되어야 합니다.
물론 대부분의 오픈 소스 프로젝트 메인테이너는 이를 몰라서 안 하는 것이 아닙니다. 릴리스를 할 때 그 동안의 커밋들을 뒤져보며 체인지로그를 적는 일이 하도 귀찮고 시간이 들기 때문에 포기하는 경우가 많습니다. 체인지로그는 방학 때 일기 쓰는 것과 비슷합니다. 제 때 조금씩 써두면 큰 일이 아닌데, 나중에 몰아서 하려고 하면 양도 많은데다 시간이 많이 지나 기억도 잘 나지 않으니 큰 일이 되는 것입니다.
따라서 체인지로그는 매 커밋, 또는 매 기능 추가(보통은 풀 리퀘스트 단위)마다 기록해두는 것이 좋은 프로세스입니다.
그러나 그러한 프로세스가 있어도 제 때 체인지로그를 남겨둬야 한다는 사실 자체를 기여자 뿐만 아니라 메인테이너까지도 잊어버리는 경우도 많습니다. 이런 실수를 크게 줄이는 팁이 있는데, 바로 CI 빌드 스크립트로 규칙을 지키지 않으면 빨간 불이 뜨도록 코딩하는 것입니다.
예를 들어, 트래비스 CI를 이용한다면 프로젝트의 .travis.yml 설정 파일에 다음과 같은 bash 코드를 포함시켜서, 풀 리퀘스트나 커밋에 체인지로그가 없을 경우 오류가 나게 할 수 있습니다.
git diff --name-only "$TRAVIS_COMMIT_RANGE" | grep CHANGELOG
TRAVIS_COMMIT_RANGE는 Travis CI에서 정의해주는 환경 변수로, 빌드마다 변경된 Git 커밋 범위로 정의됩니다. 예를 들어 풀 리퀘스트의 빌드라면 그 풀 리퀘스트에 들어있는 첫 커밋부터 마지막 커밋까지로 정의됩니다. git diff --name-only "$TRAVIS_COMMIT_RANGE" 명령은 변경된 파일의 목록을 출력합니다. 풀 리퀘스트 빌드라면, 풀 리퀘스트에서 손 댄 모든 파일 목록이 나옵니다. 이어지는 | grep CHANGELOG는 그 파일 목록 중에 CHANGELOG 파일이 포함되었는지 확인합니다. 만약 풀 리퀘스트가 CHANGELOG를 남기지 않았다면 grep이 0이 아닌 종료 코드와 함께 끝날 것이므로 빌드는 실패하게 됩니다.
어떤 패치는 따로 체인지로그를 남기지 않아도 되는 경우도 있습니다. 간단한 오타 수정이나 CI 빌드 설정을 고치는 것처럼 이용자들이 쓰는 기능에 영향을 주지 않는 패치가 그렇습니다. 그럴 때를 위해서 커밋 메시지에 특정한 키워드를 포함시키면 검사를 우회할 수 있게 개선하는 것도 좋은 생각입니다. 스포카의 오픈 소스 프로젝트에서는 보통 [changelog skip]이라는 문자열1이 커밋 메시지에 포함되면 체인지로그를 검사하지 않도록 해두는 편입니다.
if git show --format=%B --quiet "$TRAVIS_COMMIT_RANGE$TRAVIS_TAG" | grep '\[changelog skip\]' > /dev/null; then
echo "Skip changelog checker..."
else
git diff --name-only "$TRAVIS_COMMIT_RANGE" | grep CHANGELOG
fi
버전 정책
버전 문자열도 코드
소프트웨어 버전 번호는 여러 곳에서 나타납니다. CLI 프로그램이라면 -v/--version 옵션으로 볼 수도 있고, 패키지 시스템의 메타데이터 파일에도 포함되며, man 페이지나 HTML로 빌드되는 문서에도 나타납니다. 따라서 버전 번호도 코드의 상수 데이터를 대하듯 해야 합니다. 중복을 줄여서 전체 코드에서 최소한으로 하드코딩되게 하지 않으면, 새 버전을 릴리스할 때 버전 번호를 올리지 않고 예전 버전 번호 그대로 릴리스해버리는 실수를 하기 쉽습니다.
하스켈의 카발 같은 몇몇 패키지 시스템은 해당 패키지 시스템이 패키지 메타데이터에 적힌 버전 번호를 런타임에 알 수 있게 API를 제공하기도 합니다. 그런 API가 있다면 최대한 활용하는 것이 좋습니다.
그런 장치가 없다면 버전 번호를 누구라도 쉽게 찾을 수 있는 곳에 위치시키는 것이 좋습니다. 파이썬이라면 pkg/__init__.py 파일에 __version__이라는 상수로 남겨두는 것이 관례입니다. 파이썬의 패키지 메타데이터는 setup.py라는 별도 파일에도 기술되어야 하는데, 다행히 setup.py 파일은 파이썬 스크립트이므로 프로그램 코드에 들어있는 버전 번호 데이터를 읽어서 활용할 수 있습니다.
릴리스한 버전마다 태그 달기
대부분의 버전 관리 시스템에는 태그 기능이 있습니다. 새 버전을 릴리스하고 나서는, 그 릴리스에 포함된 마지막 커밋에 태그를 추가해야 합니다. 이 원칙은 “많이 알려져 있다고” 알려져 있지만, 의외로 모르는 경우도 많습니다. 최근의 웹 기술 기반의 서비스는 버전 번호를 정하지 않고 연속적으로 배포하는 프랙티스를 채택하는 경우가 많기 때문입니다.
버전 번호를 정해서 릴리스하는 프로젝트의 경우, 모든 릴리스 자동화 및 프로세스를 태그를 중심으로 돌아가게 하는 편이 좋습니다. CI 소프트웨어·서비스나 깃허브 같은 코드 호스팅 사이트 등, 많은 소프트웨어 프로젝트를 돕는 도구들이 릴리스마다 태그가 생긴다는 가정을 존중하기 때문입니다. 이상적으로는 태그를 푸시하는 것이 사람이 릴리스 과정에 수동으로 개입하는 마지막이자 최소한의 절차이도록 발전시킬 수 있습니다.
그 정도로 자동화하기 힘들다고 하더라도, 버전 관리 시스템의 태그와 실제 릴리스 절차가 일치하는지 CI 빌드에서 검사할 수는 있습니다. 아래는 파이썬 패키지 시스템에서 패키지 이름이나 버전 번호 등의 메타데이터를 기술하는 파일인 setup.py에 태그 이름과 같은 버전 번호가 적혀있는지 검사하는 스크립트입니다.
[[ "$TRAVIS_TAG" = "" ]] || [[ "$TRAVIS_TAG" = "$(python setup.py --version)" ]]
비슷하게, 아래는 러스트 패키지 시스템인 카고에서 패키지 메타데이터를 기술하는 Cargo.toml 파일에 적힌 버전 번호를 검사하는 스크립트입니다.
[[ "$TRAVIS_TAG" != "" ]] || grep "\"${TRAVIS_TAG//./\.}\"" Cargo.toml
아래는 하스켈 패키지 시스템인 스택에서 패키지 메타데이터 파일에 적힌 버전 번호를 검사하는 스크립트입니다. (PKG는 해당 프로젝트의 패키지 이름으로 치환합니다.)
[[ "$TRAVIS_TAG" = "" || "'$TRAVIS_TAG'" = "$(stack query locals PKG version)" ]]
다음 버전 준비는 새 버전 릴리스의 일환
메인테이너가 둘 이상일 경우, 혹은 메인테이너가 혼자여도 새 버전 릴리스를 뜸하게 하는 경우, 생각보다 흔하게 하는 실수가 버전을 겹치게 하거나 한 버전을 빼먹고 다음 버전 번호를 고르는 것입니다. 예를 들어 마지막으로 릴리스한 버전이 1.2.3이라면, 1.2.3 버전을 한 번 더 릴리스하려고 시도하거나 (이는 다행히 릴리스 과정 중에 실수를 깨닫게 되긴 하지만 헛수고를 하게 됩니다), 1.2.4 버전을 빼먹고 1.2.5 버전을 릴리스하는 실수입니다.
그런 실수가 흔한 까닭은 마지막으로 릴리스한 최신 정식 버전이 무엇인지 확인하기 번거롭기 때문입니다. 물론, 항상 릴리스 전에는 마지막 정식 버전이 무엇이었는지 확인한다는 프로세스를 정해도 됩니다. 하지만 실수를 방지하는 더 좋은 방법은, 다음 버전 준비를 릴리스 과정의 일부로 포함하는 것입니다.
예를 들어, 마지막으로 릴리스한 버전이 1.2.3이라면, 이번에 1.2.4 버전을 릴리스하고 나서 소스 코드 내의 버전 문자열 등을 1.2.5로 올려두는 커밋을 하는 것까지 릴리스 과정의 마지막에 포함하면 됩니다. 버전 번호를 올리는 작업을 흔히 버전 범프(version bump)라고 합니다.
이 규칙의 장점은 특히 위에서 제안한 체인지로그(changelog)와 함께할 때 더 큽니다. 1.2.4 버전을 릴리스한 직후에, 소스 코드의 모든 버전 문자열을 1.2.5로 올리고, CHANGELOG 파일의 맨 위에도 아래와 같이 1.2.5 버전의 제목을 추가하면 됩니다.
diff a/CHANGELOG.rst b/CHANGELOG.rst
--- a/CHANGELOG.rst
+++ b/CHANGELOG.rst
@@ -1,6 +1,12 @@
Changelog
=========
+Version 1.2.5
+-------------
+
+To be released.
+
+
Version 1.2.4
-------------
diff a/proj/__init__.py b/proj/__init__.py
--- a/proj/__init__.py
+++ b/proj/__init__.py
@@ -1,2 +1,2 @@
-__version__ = '1.2.4'
+__version__ = '1.2.5'
이렇게 미리 다음 릴리스 버전을 위한 항목을 CHANGELOG 파일에 만들어두고, 그 안에 “to be released” 같은 아직 릴리스되지 않은 버전이라는 힌트까지 남겨두면, 메인테이너 자신과 컨트리뷰터에게 마지막 정식 릴리스 버전이 무엇이었는지 신경을 덜 써도 되게 해줍니다. 앞서 제안한 것처럼 체인지로그를 적었는지 검사하는 빌드 스크립트까지 함께할 경우, 풀 리퀘스트를 처음으로 올린 기여자의 작업 순서는 보통 아래처럼 바뀝니다.
- 체인지로그를 빼먹는다.
- 빌드가 깨지는 것을 확인한다.
- 그렇다면 체인지로그를 어느 항목에다 넣어야 할지 생각한다.
- CHANGELOG 파일을 열어보고 이미 “to be released”라 적힌 항목을 확인한다.
- 큰 고민 없이 해당 항목에 체인지로그를 남긴다.
물론 이 프로세스에 익숙해진 메인테이너는 풀 리퀘스트를 올릴 때부터 체인지로그를 기록하는 습관이 생기므로 점차 빌드가 실패하는 것을 보지 않게 됩니다.
단, 실제로 해당 버전을 릴리스할 때는 “to be released”라는 문구는 실제 릴리스된 날짜 등으로 대체되어야 합니다. 이 역시 까먹고 실수할 수 있으므로, CI 빌드 스크립트에 이를 검사하는 스크립트를 넣어두면 좋습니다.
[[ "$TRAVIS_TAG" = "" ]] || ! grep -i "to be released" CHANGELOG
TRAVIS_COMMIT_RANGE와 마찬가지로 TRAVIS_TAG 역시 트래비스 CI가 빌드마다 정의해주는 환경 변수입니다. Git 태그에 대한 빌드인 경우 태그 이름으로 정의되며, 그 외에는 정의되지 않습니다.
버그 패치를 위한 별도 브랜치 운영
1.0.0에 추가된 기능이 있는데, 1.0.1, 1.0.2 등의 버전을 지나 다음 마이너 버전인 1.1.0이 출시된 뒤에서야 그 기능의 버그를 발견했을 때는 어떻게 할까요? 메인테이너 입장에서 가장 속 편한 대응은 그 버그를 수정한 1.1.1 버전을 릴리스하는 것입니다.
하지만 1.1.0의 어떤 변경을 당장 도입하기 어려워서 1.0대의 최신 버전으로 유지하고 있는 이용자들은 어떨까요? 버그가 해당 이용자들에게도 심각하다면, 아래와 같이 어떤 쪽도 행복하지 않은 선택지 중에서 고민해야 합니다.
- 위험을 부담하고 시간을 들여 자신의 코드가 1.1.0와 조화되도록 고칩니다. 이 선택은 암시적으로 일정 기간 버그를 감수하는 선택을 내포할 때가 많습니다. 작업 시간이 오래 걸리는데, 그 동안 버그를 감수하는 것이기 때문입니다.
- 쓰고 있는 1.0대 버전의 라이브러리를 포크하여 버그를 직접 고치거나 1.1.1의 변경을 1.0대 코드에 이식합니다.
좀더 골치아픈 경우는 다음 메이저·마이너 버전을 준비하고 있는데 이전에 출시한 버전의 버그를 고쳐야 하는 상황입니다. 예를 들어 1.2.0 버전을 준비중인데 1.1.1의 버그를 고쳐야 하는 경우입니다. 이 때에도 메인테이너 입장에서만 속 편한 대응을 하자면, 그 버그의 패치를 작업중인 master 브랜치에 넣고, 1.2.0 버전과 함께 릴리스하기로 합니다. 이렇게 되면 이용자는 더 고된 선택을 해야 합니다. 앞선 두 선택지의 더욱 터프한 버전입니다.
- 매우 큰 위험을 부담하여 정식으로 릴리스도 되지 않은 1.2대 개발 버전을 직접 빌드해서 사용합니다. 이 선택은 또 다른 더 큰 버그들을 만나기 쉽습니다.
- 쓰고 있는 1.1대 버전의 라이브러리를 포크하여 버그를 직접 고치거나, 1.2대 개발 버전에 들어있는 버그 패치를 1.1대 버전에 이식합니다. 버그 패치라고는 하지만 이용자들에게 노출된 적은 없기 때문에, 운이 나쁘면 그 버그 패치를 적용해도 문제는 해결되어 있지 않을 수도 있습니다.
이런 문제를 극복하기 위해, 릴리스마다 버전 번호를 정하는 전통적인 소프트웨어 프로젝트는 대부분 메이저 및 마이너 버전 별로 관리 브랜치를 두는 경우가 많습니다. 예를 들어 1.1.0을 릴리스하는 순간 master는 1.2대 내지는 2.0대를 준비하기 위한 브랜치가 되고, 1.1대의 버그를 고치기 위한 1.1-maintenance 브랜치도 만들게 됩니다.
즉, (마지막 번호가 *.*.0인) 새로운 메이저 및 마이너 버전을 릴리스할 때 아래 작업들을 하게 됩니다. 여기서는 1.1.0 버전을 릴리스한다고 가정합니다.
master는 1.2.0 버전으로 범프합니다. CHANGELOG 파일에도 1.2.0 버전을 위한 빈 항목을 만듭니다. 이제 이 브랜치에 추가되는 커밋은 모두 1.2.0 버전에서 처음으로 선보일 변경만 포함해야 합니다.- 1.1.1, 1.1.2 등의 1.1대 버전의 버그를 고치는 커밋을 모으기 위한
1.1-maintenance브랜치를 새로 만들고, 마찬가지로 1.1.1 버전으로 범프합니다. CHANGELOG 파일에도 1.1.1 버전 항목을 만듭니다.
이후로는 1.1대 이후에 생긴 변경(주로 버그 패치)은 1.1-maintenance 브랜치에 넣으면 됩니다. 그리고 1.1.1 버전을 릴리스할 때 아래 작업들을 하게 됩니다.
- 1.1.1 버전을 릴리스합니다.
1.1-maintenance브랜치의 버전을 1.1.2로 범프합니다. CHANGELOG에도 1.1.2 버전을 위한 항목을 만듭니다. 여기까지는 같습니다.master브랜치에1.1.1태그를 머지합니다. 이 때 CHANGELOG 파일이 맨 윗 부분에 충돌이 있을 수 있습니다. 1.1.1 버전 항목 위에 1.2.0 버전 항목이 놓이도록 손으로 해결해주면 됩니다.
이렇게 1.1-maintenance 브랜치와 master 브랜치를 함께 운영하면 1.2.0 버전이 출시하게 될 때는 그 동안에 알려져 있던 1.1대 버전의 모든 버그는 1.2.0 버전에서도 고쳐져 있게 됩니다.
패키지 저장소에 업로드 자동화
라이브러리 프로젝트라면 해당 프로그래밍 언어의 공식 패키지 저장소에 업로드하는 절차가 필요합니다. 예를 들어, 파이썬은 PyPI, 자바스크립트는 NPM이 되겠습니다. 라이브러리 릴리스에서 가장 중요한 작업이기 때문에 이 절차를 잊어버릴 일은 없지만, 사람이 손으로 할 일을 줄이면 아무래도 릴리스 프로세스 전반에서는 실수를 덜 하게 됩니다.
트래비스 CI 같은 서비스에서는 태그 빌드가 성공할 경우 주요 패키지 저장소에 자동으로 업로드해주는 기능을 제공하기도 합니다. 하지만 사용하고 있는 CI 소프트웨어·서비스가 그런 기능을 제공하지 않더라도, 직접 스크립트를 짜서 자동화하는 것도 얼마든지 가능합니다.
빌드 자동화
네이티브 바이너리
파이썬이나 자바스크립트 같은 스크립트 언어의 경우 소스 코드 형태로 라이브러리나 애플리케이션을 배포하는 것이 일반적이지만, 고(Go)나 하스켈, 러스트 같이 네이티브 바이너리로 컴파일되는 언어의 경우에는 경우 소스 코드 뿐만 아니라, 이용자가 직접 빌드하지 않고도 손쉽게 써볼 수 있도록 미리 빌드된 바이너리를 제공하는 것이 일반적입니다.
요즘에는 저장 공간의 비용이 저렴해진 덕에 애플리케이션이 의존하는 모든 라이브러리까지 통째로 정적 링크하여 배포하는 프로젝트도 늘고 있습니다. 최근에는 도커처럼 가상화된 환경에서 애플리케이션을 쓸 일이 많다보니, glibc 대신 musl 같은 가벼운 대안을 쓰는 환경도 많습니다. 이런 부분도 고려하다 보면 C 런타임까지 모두 정적 링크하여 이용자의 실행 환경과 최대한 독립적으로 쓸 수 있는 실행 바이너리를 만드는 게 도움이 됩니다.
모든 것을 정적 링크하게 되면 단 하나의 파일만 배포하면 된다는 장점도 누릴 수 있습니다. 다만 압축을 하지 않고 배포하면 다소 부담스러운 크기가 될 수도 있는데, 이러한 문제를 완화하기 위해서 컴파일러의 -Os 같은 파일 크기 최적화 옵션이나 UPX 같은 실행 파일 전문 압축 프로그램을 활용해볼 수 있습니다.
아래 스크립트는 .travis.yml 설정 파일에서 매 버전 릴리스(태그 빌드)마다 리눅스와 맥OS용 네이티브 바이너리를 정적 링크로 빌드하여 UPX로 압축까지 하는 예시입니다 (PROG는 프로젝트에 맞게 치환).
if [[ "$TRAVIS_TAG" != "" ]]; then
cargo build --release
if [[ "$TRAVIS_OS_NAME" = "linux" ]]; then
upx-ucl -9 target/release/PROG
elif [[ "$TRAVIS_OS_NAME" = "osx" ]]; then
upx -9 target/release/PROG
fi
mv target/release/PROG \
"target/release/PROG-$(uname -s | tr '[A-Z]' '[a-z]')-$(uname -m)"
fi
다만, 모든 의존성을 정적 링크하여 배포하면 편리하기는 하지만, 중요한 보안 업데이트를 따라가기 힘들다는 단점도 있으니 유의해야 합니다. 여건이 된다면 정적 링크한 실행 바이너리는 차선책으로 제공하고, 널리 쓰이는 리눅스 배포판들을 위한 패키지를 제공하는 것이 좋습니다. 예를 들어 PPA나 .deb 패키지를 제공한다면 우분투나 데비안 이용자는 구태여 범용 바이너리를 다운로드하지 않을 것입니다.
파이썬 같은 스크립트 언어에서도 C 확장을 포함하는 라이브러리나 애플리케이션을 배포할 때는 네이티브 바이너리를 함께 제공하는 편이 좋습니다. 가령 파이썬이라면 컴파일된 C/C++ 바이너리를 포함한 라이브러리를 패키징하기 위한 .whl 포맷을 통해 네이티브 바이너리를 패키징할 수 있습니다.
윈도 이용자는 C/C++ 소스 코드를 빌드할 수 있는 개발 환경이 갖춰지지 않은 경우가 많으므로, 윈도용 바이너리를 함께 배포해야 이용자가 편하게 설치할 수 있습니다. 트래비스 CI 외에도 윈도 환경에서 CI 빌드를 할 수 있게 해주는 앱 베이어 같은 서비스를 함께 활용하면 매 버전 릴리스마다 윈도용 바이너리가 자동으로 빌드되도록 자동화할 수 있습니다.
다음은 매 빌드마다 파이썬 패키지의 .whl 바이너리를 빌드하여 아티팩트로 남기는 appvayor.yml 설정 예시입니다.
after_test:
- python setup.py bdist_wheel
artifacts:
- path: dist\*
빌드 매트릭스
네이티브 바이너리를 제공한다면 이용자에게는 편하겠지만, 메인테이너에게는 큰 짐이 됩니다. 예를 들어 32비트 및 64비트 윈도, 맥OS, 리눅스를 지원해야 한다면 어떨까요? 그런데 파이썬 확장 모듈이어서 파이썬 2.7부터 최신의 파이썬 3.6까지 지원해야 한다면? (win32, win64, darwin, linux) ✕ (python2.7, python3.4, python3.5, python3.6) 조합에 해당하는 총 16개의 네이티브 바이너리를 만들어내야 합니다.
이럴 때 쓰기 위한 기능이 빌드 매트릭스입니다. 위에서 말한 것과 같이, 여러 언어 버전, 플랫폼 종류 등을 나열하면, 그 모든 조합에 대한 빌드를 실행하게 해주는 기능입니다. 트래비스 CI도 빌드 매트릭스 기능을 제공하고, 앱 베이어도 제공합니다. 트래비스 CI는 리눅스와 맥OS를 지원하고, 앱 베이어는 윈도를 지원하므로, 트래비스 CI와 앱 베이어를 함께 쓰고, 양쪽에서 빌드 매트릭스를 적용하면 주요 플랫폼에 대한 매우 다양한 바이너리를 자동으로 빌드할 수 있습니다. 이는 메인테이너 혼자서 손으로 만든다면 매우 지난한 작업이 될 것입니다.

참고로 빌드 매트릭스는 꼭 릴리스를 자동화하는 것 뿐만 아니라, 개발 과정에서도 꾸준히 지원하는 모든 플랫폼에서 자동화된 테스트를 돌려 볼 수 있다는 점에서도 매우 유용합니다.
깃허브 릴리스
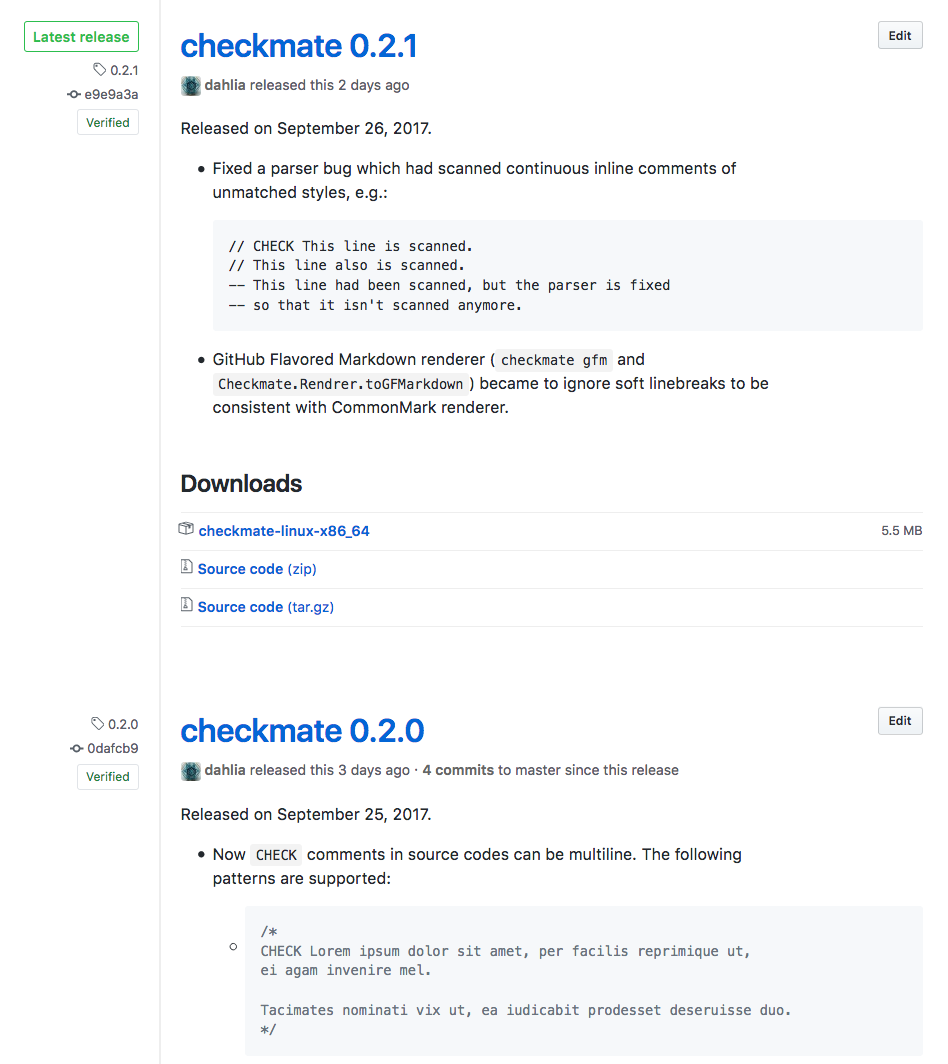
바이너리를 열심히 빌드하더라도 이용자가 받을 수 있으려면 어딘가에 올려둬야 합니다. 깃허브 릴리스는 딱 그런 용도를 위해 만들어진 기능입니다. Git 태그 하나에 그 태그의 소스 코드로부터 빌드된 파일들을 올릴 수 있게 되어 있습니다. 예를 들어, 1.2.3 버전의 태그를 만들어서 푸시한 뒤에, 1.2.3 태그에 1.2.3 버전의 윈도용 실행 파일, 맥OS용 실행 파일, 리눅스용 실행 파일, 소스 코드 타볼을 올리는 식으로 쓸 수 있습니다.
깃허브의 다른 많은 기능처럼 깃허브 릴리스 역시 API로 모든 기능을 쓸 수 있기 때문에 자동화에 용이합니다. 워낙 많이 쓰이는 기능이기 때문에 많은 CI 소프트웨어·서비스가 깃허브 릴리스 연동 기능을 기본으로 갖추고 있기도 합니다.
트래비스 CI도 깃허브 릴리스에 빌드 결과물을 올려주는 기능이 있습니다. 만약 사용하는 CI 소프트웨어·서비스가 깃허브 릴리스 연동 기능을 갖추지 않았거나 내장된 기능보다 복잡한 연동이 필요할 경우 github-release 같은 CLI 유틸리티를 활용할 수 있습니다.
다음은 트래비스 CI의 깃허브 릴리스 연동 기능과 github-release 및 submark 유틸리티를 함께 사용하여, 매 태그 빌드마다 해당 버전의 바이너리를 올리고, 체인지로그의 해당 버전 섹션만 추출하여 깃허브 릴리스의 설명으로 채워넣는 .travis.yml 설정 예시입니다 (PROG는 프로젝트에 맞게 치환).
deploy:
# 매 태그 빌드마다 컴파일된 바이너리(build/PROG-*)를 깃허브 릴리스에 올린다.
- provider: releases
api_key: "$GITHUB_TOKEN"
file_glob: true
file: build/PROG-*
skip_cleanup: true
on:
tags: true
# 만들어진 깃허브 릴리스 항목의 내용을 좀더 보충한다.
after_deploy:
# `github-release` 프로그램의 바이너리를 다운로드하여 설치한다.
- |
pushd /tmp
curl -OL \
https://github.com/aktau/github-release/releases/download/v0.7.2/linux-amd64-github-release.tar.bz2
tar xvfj linux-amd64-github-release.tar.bz2
mkdir -p ~/bin/
mv bin/linux/amd64/github-release ~/bin/
chmod +x ~/bin/github-release
popd
# `submark` 프로그램도 설치한다.
- |
curl -L -o ~/bin/submark \
https://github.com/dahlia/submark/releases/download/0.1.0/submark-linux-x86_64
- chmod +x ~/bin/submark
# `submark`를 써서 체인지로그의 해당 버전 섹션만 추출한다.
- submark -o /tmp/release-note --h2 "Version $TRAVIS_TAG" -O CHANGELOG.md
- cat /tmp/release-note
# `github-release`를 써서 이미 만들어진 릴리스 항목의 설명을 추출한 체인지로그로 보충한다.
- |
github-release edit \
--user "${TRAVIS_REPO_SLUG%%/[^/]*}" \
--repo "${TRAVIS_REPO_SLUG#[^/]*/}" \
--tag "$TRAVIS_TAG" \
--name "checkmate $TRAVIS_TAG" \
--description "$(cat /tmp/release-note)"
도커 허브 자동화 빌드
서버 소프트웨어의 경우 네이티브 바이너리 형태보다는 도커 이미지 형태로 배포하는 게 표준화 측면에서도 편리함 측면에서도 더 낫습니다. 애초에 네이티브 바이너리로 빌드할 수 없는 언어로 제작된 소프트웨어라면 도커 이미지를 대신할 만한 형태도 찾기 힘듭니다.
네이티브 바이너리의 빌드를 자동화하는 것과 마찬가지로, 도커 이미지도 CI 빌드 과정에 만들고 도커 허브에 푸시하면 됩니다. 이미 이 정도로도 간단하다고 할 수 있지만, 이보다도 더 단순한 방법이 있습니다. 바로 도커 허브의 자동화 빌드 기능을 활용하는 것입니다.
자동화 빌드는 이미지 저장소와 비슷한 개념이지만, 푸시는 못 하고 풀만 가능합니다. 이미지를 만들어서 저장소에 docker push하는 대신, 자동화 빌드 저장소는 첫 설정 시에 원본 Git 저장소를 입력으로 받아, 해당 Git 저장소에 변경이 일어날 때마다 알아서 소스 트리를 받아 Dockerfile에 따라 이미지를 빌드하게 됩니다. 즉, 사람이 이미지를 빌드하고 푸시하는 작업을, 사람이 이미지로 빌드할 원본 소스 트리를 푸시하면 그걸 받아서 알아서 이미지로 빌드하는 작업으로 대체해줍니다.
자동화 빌드의 트리거 설정을 통해 특정 정규식에 부합하는 태그가 만들어졌을 때만 이미지를 빌드하게 하거나, master 브랜치에 푸시했을 때만 이미지를 빌드하게 하는 식의 활용이 가능합니다. 이용자 입장에서는 docker pull만 하므로 해당 저장소가 일반적인 도커 이미지 저장소인지 자동화 빌드 저장소인지 신경 쓸 필요도 없습니다.
도커 허브의 자동화 빌드 저장소는 공개 저장소의 경우 무료라는 장점도 있습니다. 범용 CI 빌드와 독립적으로 운영되므로 CI 빌드의 수행 시간를 짧게 유지하는 데에도 도움이 됩니다. 무엇보다 직접 이미지를 빌드하고, 저장소에 푸시하기 위해 인증을 자동화하는 등의 번거로운 작업을 전혀 하지 않아도 된다는 점이 좋습니다.
문서화
매 릴리스마다 준비해야 하는 것은 바이너리나 패키지 외에도 많습니다. 그 중 하나가 바로 문서입니다.
문서의 용도에 따라 정도의 차이는 있으나, 소프트웨어 제품의 문서는 소프트웨어 자체의 업데이트와 발을 맞추어야 합니다. 쓰고 있는 라이브러리의 오래 전 문서를 참고해서 기능을 만들고 나서 보니, 그 라이브러리의 최신 버전에서는 내가 방금 만든 기능을 탑재하고 있다는 사실을 깨닫고 허탈해진 경험, 문서가 쓰인 이후에 라이브러리 동작이 바뀐 줄 모르고 썼다가 운영 도중 예기치 못한 버그를 고쳐야 했던 경험 등. 소프트웨어 자체만 업데이트 되고 문서에는 반영되지 않아 낭패를 본 기억은 현업 프로그래머라면 다들 있을 것입니다.
문서와 소프트웨어의 변경을 발 맞추기 위해서 꼭 강조하고 싶은 원칙이 하나 있습니다. 문서를 소스 코드 저장소와 함께 보관하세요! 가령 소프트웨어 문서를 별도 위키에 적는 것은 구성원의 남다른 의지력과 규범 의식 등을 자신하지 않는 한 문서 내용을 잘 갱신하지 않겠다는 것과 같습니다.
문서를 소스 코드 저장소에 함께 보관하면 이점이 많습니다. 우선, 과거 버전의 소스 코드를 살펴볼 때, 그 당시의 문서도 함께 볼 수 있습니다. 작업자가 작업하는 소스 코드 근처에 문서가 있으면 문서를 갱신해야 한다는 것을 덜 까먹기도 합니다. 또한 문서, 그리고 문서와 소스 코드의 관계에 대해서 린트(lint) 같은 검사를 수행할 수도 있습니다. 예를 들어 외부에 공개되는 API에 함수에는 항상 그에 대응하는 문서가 있는지를 매 빌드마다 검사할 수 있습니다. 무엇보다 프로젝트에 참여하는 사람들이 문서도 소프트웨어의 일부라는 인식을 주는 데에도 도움이 됩니다.
문서에도 체인지로그와 비슷한 원칙과 검사 장치를 적용할 수 있습니다. 기능 추가 단위(풀 리퀘스트 등)에 코드 뿐만 아니라 관련된 문서의 변경도 함께 하도록 원칙을 세우고, 문서를 갱신하지 않은 것이 분명하면 빌드가 실패하게 만들면 됩니다.
소프트웨어 코드가 저장소에 있다고 해서 이용자가 저장소에서 직접 소프트웨어를 받아야만 한다는 뜻은 아닌 것처럼, 문서를 저장소에 담는다고 해서 이용자가 문서를 저장소 안에서 뒤져야 한다는 뜻은 아닙니다. 소프트웨어를 빌드해서 바이너리나 패키지 형태로 가공해서 어딘가에 올려두는 것처럼, 문서 역시 자동화된 빌드 과정을 통해 가공하여 공식 홈페이지 등에 올리는 과정이 필요합니다. 이어지는 내용은 그러한 가공을 쉽게 자동화하는 팁입니다.
깃허브 페이지
문서의 포맷과 무관하게 일반적으로 활용할 수 있는 기능으로 깃허브 페이지가 있습니다. 이미 널리 알려져 있지만 간단히 소개하자면, 깃허브 저장소에 gh-pages라는 브랜치를 만들어서 그 안에 정적 웹 사이트 파일들을 업로드하면 이를 서빙해주는 기능입니다. 깃허브 저장소가 foo/bar라면 foo.github.io/bar/라는 URL로 웹 사이트를 출판하게 됩니다. 소유한 도메인 이름이 있다면 연결할 수도 있습니다.
웹 사이트를 업로드하는 방식이 특정한 브랜치에 푸시하는 것이기 때문에 스크립팅하기 매우 쉽습니다. 트래비스 CI는 깃허브 페이지스 연동 기능도 제공합니다. 이를 활용하면 사람이 손으로 생각날 때마다 문서를 업데이트하는 것이 아니라, 매 릴리스마다, 혹은 아예 매 푸시마다 문서를 갱신하도록 자동화할 수 있습니다.
리드 더 독스
파이썬 커뮤니티에서는 깃허브 페이지보다는 리드 더 독스(이하 RtD)라는 서비스를 더 많이 씁니다. pip, 리퀘스츠, 장고, 셀러리 등 많은 프로젝트가 RtD에 문서를 올리고 있습니다.
RtD는 소스 코드 저장소에 푸시가 될 때마다 소스 트리에 있는 문서를 정적 웹 사이트로 빌드한 뒤 출판해주는 서비스입니다. 문서 빌드를 알아서 해주기 때문에 CI 빌드에서 문서를 빌드할 필요가 없습니다. “깃허브 페이지 : 도커 이미지 저장소 = RtD : 도커 자동화 빌드 저장소” 정도의 구도라고 볼 수 있습니다.
물론 RtD가 임의의 포맷으로 작성된 문서를 찰떡 같이 알아듣고 웹 사이트로 출판해주는 것은 아닙니다. 파이썬 생태계를 중심으로, 문서화 플랫폼으로 독보적인 지위에 있는 스핑크스 포맷의 문서만 지원합니다. RtD가 파이썬 커뮤니티에서 많이 쓰이는 이유도 스핑크스가 파이썬으로 구현되어 있고, 파이썬 생태계에서 스핑크스가 사실상의 표준 문서화 도구로 자리매김하고 있기 때문입니다. 그러나 하스켈 스택이나 GHC처럼 파이썬과 관계 없는 소프트웨어에서도 충분히 쓸만합니다.
그 외에도 RtD는 동시에 여러 버전에 대한 문서를 출판하거나, 안정화 버전, 개발 버전 등과 같이 스테이지 별로 문서를 동시 출판하거나, 다국어 문서를 출판하는 등의 기능을 제공하고 있어, 문서의 역할이 큰 프로젝트에서 도입을 고려할 만합니다.
-
트래비스 CI 등 많은 CI 서비스·소프트웨어가 채택한
[ci skip]키워드를 흉내낸 것입니다. ↩
스포카에서는 “식자재 시장을 디지털화한다” 라는 슬로건 아래, 매장과 식자재 유통사에 도움되는 여러 솔루션들을 개발하고 있습니다.
더 나은 제품으로 세상을 바꾸는 성장의 과정에 동참 하실 분들은 채용 정보 페이지를 확인해주세요!