
스포카 개발팀 문성원입니다. 오늘은 Celery를 통해 오랜 시간이 걸리는 작업을 어떻게 개선하는지를 실례를 통해 알아보겠습니다.
Why Celery?
지난주에 저희는 대량의 PDF 파일을 만들어서 관리자용 웹 페이지를 통해 내려받게끔 하는 기능을 추가해야 했습니다. 기존에 이미지파일을 압축해서 HTTP 응답으로 내려주던 핸들러가 있었기에, 압축 루틴을 PDF 생성 루틴으로 바꿔치기만 하면 되는 아주 간단한 일이라고 생각했죠. (실제로 저희 팀의 유병석님이 reportlab과 pyPdf를 사용해서 멋지게 구현하셨죠.) 대강의 얼개는 이렇습니다.
그런데 문제가 생겼습니다. 이미지를 압축해서 내려주는 것에 비해서 PDF를 만드는 데는 훨씬 많은 시간이 필요했고, 이 때문에 사용하던 서비스(Heroku)에서 타임아웃을 내버렸습니다. 요청을 처리하는 핸들러가 직접 파일을 만들어서 줄 수 없게 돼버렸습니다.
다행히 저희는 이런 문제에 대한 일반적인 해결책을 잘 알고 있었습니다. 바로 별도의 작업자(Worker)를 두는 것이지요. 시간이 오래 걸리는 PDF 생성 루틴은 웹서버와 별개로 돌아가는 작업자에게 위임하고 요청을 처리하는 핸들러는 클라이언트(웹 브라우저)에게 바로 HTTP 응답을 돌려줍니다. 생성된 파일은 Amazon S3에 올려서 완료될 때 요청자가 내려받을 수 있게 만들면 됩니다.
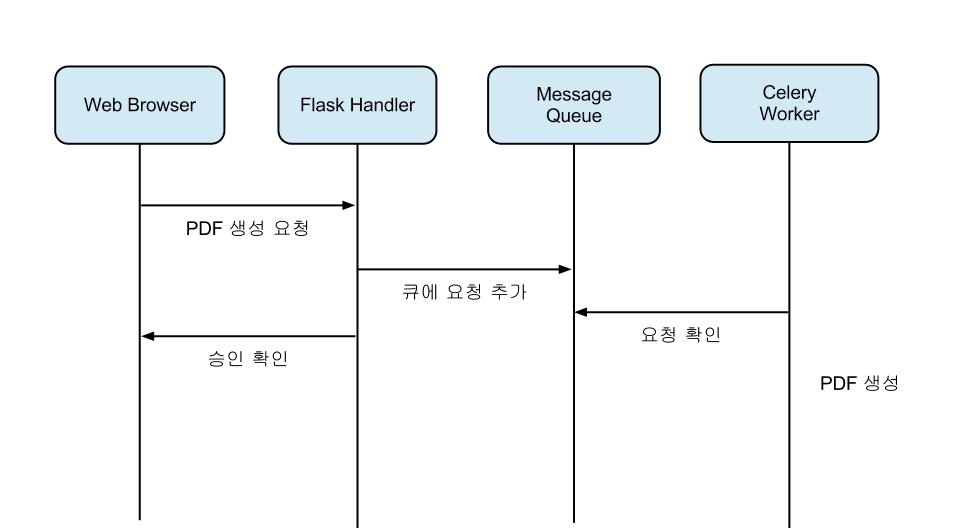
그럼 이러한 작업자는 어떻게 구현할까요? 물론 시간과 여유가 있으신 분들은 바닥부터 만들어보시는 것도 좋은 경험이겠습니다만, 저희는 그럴 시간은 없었습니다. 그래서 선택한 것이 Celery입니다. 지난 포스팅에서 인용한 Celery에 관한 소개를 보시죠.
Celery는 Python으로 작성된 비동기 작업 큐(Asynchronous task queue/job queue)입니다. 앞서 소개한 작업(Task)를 브로커(Broker, 스포카 서버는 Redis를 사용)를 통해 전달하면 하나 이상의 워커(Worker)가 이를 처리하는 구조입니다. 포인트 적립-공유에 따른 분배처리, 포스팅 기능, 페이스북/트위터 공유등의 비동기 처리가 필요한 작업을 Celery에 위임하여 처리하고 있습니다.
이 시나리오에서 작업(Task)에 해당하는 것은 PDF 생성 후 업로드입니다. 이 작업을 브로커(Broker)에 넣는 것은 요청을 받은 핸들러겠고요. 한번 고쳐진 소스를 보실까요?
Not enuogh memory
자 이제 응답이 지연될 일도 없으니 다 되었다고 생각한 저희는 테스트 환경에 배포해보았습니다. 그런데 테스트 중 이상한 에러 메시지가 떴습니다.
R14 Error에 대한 설명을 살펴보니 아무래도 PDF를 만드는 도중 메모리가 부족해진 것 같네요. 실제로 Heroku의 Dyno의 메모리 상한은 고작 512MB입니다. 하지만 우리가 만들 PDF 생산 작업은 1000 페이지당 약 1G 정도를 사용합니다.
이때 (김재석님이) 고안한 방법이 페이지를 나눠서 만드는 것입니다. Dyno가 감당할 수 있을 만큼의 페이지 단위의 작업으로 쪼갠 뒤에 다시 큐에 넣어 각기 다른 작업자가 처리하게 하는 것이죠. (물론 Dyno당 메모리 제한이기떄문에 Celery의 concurreny를 고려해야 합니다.)
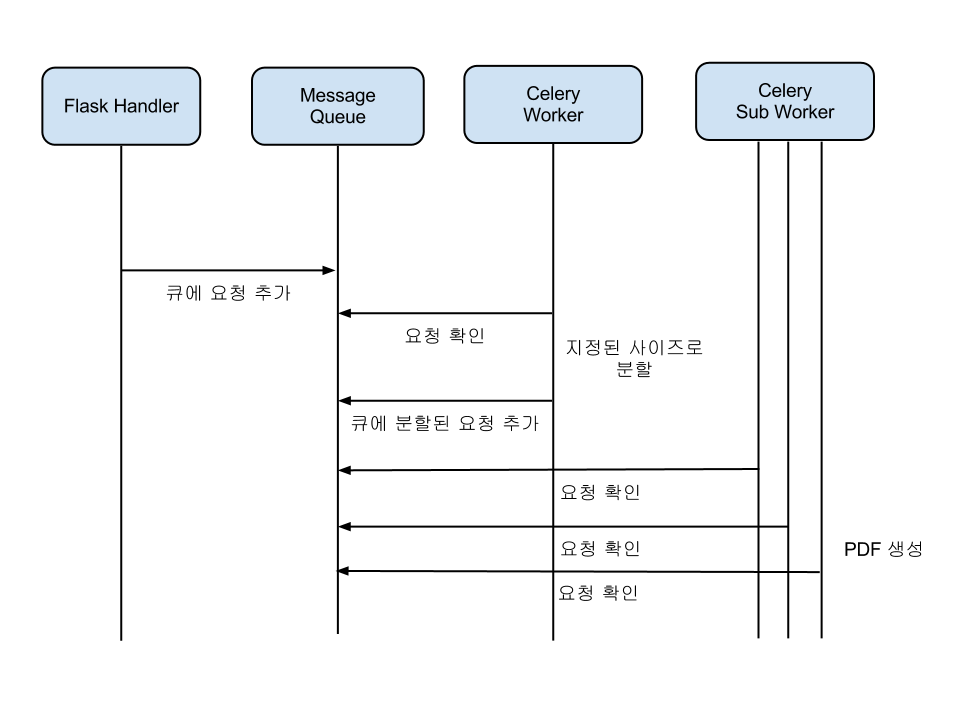
위의 개념을 적용한 코드를 함께 보시죠.
단 이 코드는 교착상태(Deadloack)을 유발할 수 있습니다. 작업 내에서 다른 작업 때문에 대기하고 있는 것은 큐라는 자원을 공유하는 이상 위험하기 때문이죠. 그래서 Celery는 이런 작업을 지원하기 위해 subtask와 chord라는 개념을 이용합니다. chord는 subtask들의 집합으로 묶여있는 작업들과, 그 작업들이 모두 끝났을 때 불릴 콜백(Callback)으로 구성됩니다. 이 chord를 통해 원래 코드를 수정하면 다음과 같습니다.
Save money
이제 적절한 수의 작업자를 Procfile에 설정해서 올리기만 하면 됩니다. 그런데 여기서 한 가지 아쉬운 점이 있습니다. 대량의 PDF를 처리하는 일은 그리 빈번히 발생하는 일이 아니므로 이를 기준으로 작업자 수를 설정하면 그만큼 노는 작업자가 늘게 됩니다. 작업자 Dyno 수에 따라 요금이 부과되는 Heroku를 사용하고 있는 저희로서는 피하고 싶은 일이죠. 그래서 작업할 때만 작업자를 명시적으로 확장(Scale Up)하고, 작업이 끝나면 줄이는(Scale Down) 할 수 있는 방법이 필요했습니다. 이때 필요한 것이 바로 heroku.py입니다. heroku.py는 Heroku의 HTTP API를 Python에서 사용할 수 있도록 싸놓은 인터페이스입니다. 이러한 heroku.py를 이용해서 작업자를 조정하는 메서드를 간단히 정의해볼까요?
마지막으로 이를 적용한 최종적인 코드는 다음과 같습니다.
스포카에서는 “식자재 시장을 디지털화한다” 라는 슬로건 아래, 매장과 식자재 유통사에 도움되는 여러 솔루션들을 개발하고 있습니다.
더 나은 제품으로 세상을 바꾸는 성장의 과정에 동참 하실 분들은 채용 정보 페이지를 확인해주세요!